092 #amld2023

The Applied Machine Learning Days are an electric magnet for those interested in the science of data science. I have been attending, contributing, and occasionally blogging about the series here since 2018. After a long-ish break, it was exciting to be at the EPFL again this week to partake in the knowledge shared at this top notch conference - this year unsurprisingly dedicated to the topic of Generative AI. You can find more highlights on the website, as well as over 600 video recordings online.
This year we gathered in the seemingly constantly reconstructed halls of the SwissTech Convention Centre to the sounds of generative music played intermezzo (though honestly, I only caught a few notes in all the din). The lovely program art was gen-created by Alexandre Sadeghi - already notorious in our circles for his Swiss Cantons as Superheroes and other catchy A.I. works.

In the spirit of the event, I am complementing my notes here with short speaker bios (in blockquotes) generated from the following prompt to Llama 2 (70B):
[INST]Here is a list of speakers and panelists from the Applied Machine Learning Days conference on Generative AI. The format is the person's first and last name, then a dash (-), then their title and current institution. Tell me, in a few words, the scientific research and impact of each of the speakers.[/INST]
parameters: {"temperature": 0.1,"truncate": 1000,"max_new_tokens": 1024,"top_p": 0.95,"repetition_penalty": 1.2,"top_k": 50,"return_full_text": false}
Open access LLMs were one of the big topics of the day. Even on the way to the conference, I was busy testing the new Code Llama model (see HuggingFace post) and contributing to a repository for tracking these topics:
 eugeneyan
eugeneyan
Welcome
Rüdiger Urbanke (detail)
Known for his work on coding theory and its applications in distributed systems and machine learning. He has made significant contributions to the field of error-correcting codes and their use in deep neural networks.
- how do we shape the educational system to prepare students for what's to come? [are you Robot-Proof?]
- at least two of the speakers will open windows into AI research at EPFL
- training on billions of dataset rows - stay tuned for a 70B parameter LLM launching at EPFL this week, EPFL labs training 7B medical LLMs every week
- deploying Llaion's Open Assistant internally
Developing Llama 2
Angela Fan (detail)
Fan develops machine learning models for natural language processing tasks, such as question answering, text classification, and dialogue generation. She has worked on applying these models to real-world problems, like improving customer service chatbots.
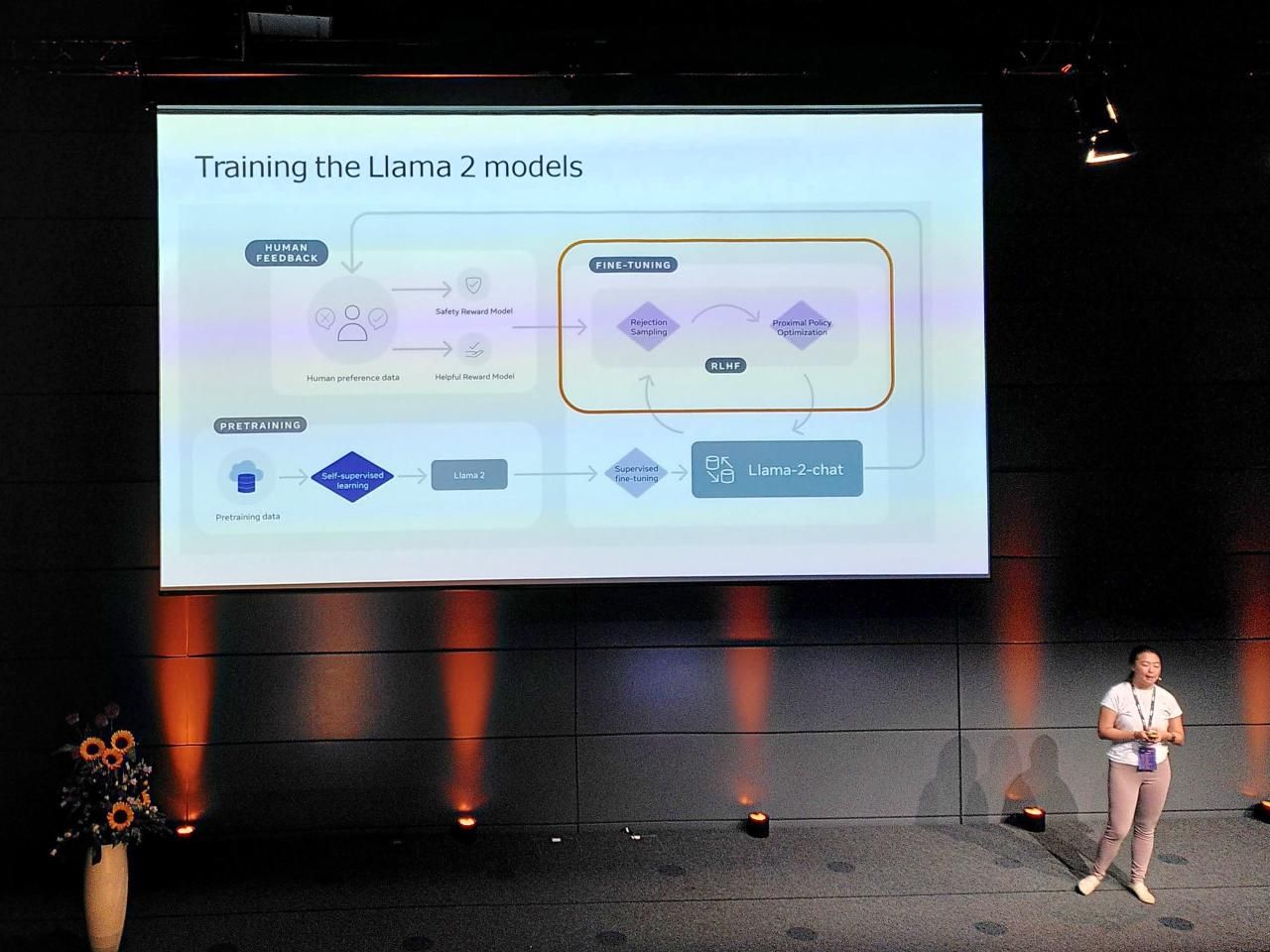
- Check out the survey of LLMs from Wayne Xin Zhao 2023
- Excited to see all the impact, based on task, chat, synthetic data
- "Llamas are meant to run free" activism
- For practical applications 7B, 13B, 70B
- Training perplexity (PPL) is 1.5x more in Llama 2
- We don't adjust much of the training rate to account for data size
- (* Really good flowchart slide in the presentation)
- Fine tuning datasets in the community to surpervise the training
- "Achieving annotation task (for quality control) is really realy hard!"
- Better to have a large number of small fine-tuning examples.
- We don't (?) use the open source model in our final training.
- We don't want our models to answer a question "how to build a bomb"
- What is the right tone for that response? = Safety Reward Model
- The model samples k-possible responses for a particular prompt.
- A reward model evaluates the quality - highest score used for back-propagation.
- "v3 of the model had poorer poetry rhyming", started using prior examples as well.
- PPO (proximate policy optimisation)
- Does the Llama model align with what people expect? We do a lot of large-scale Human feedback annotation data collection. Human trainers can look at a variety of responses, and decide which ones look better - sampling variants of the model, etc. = Helpful Reward Model
- Important that Safety + Reward steps happen tomorrow to keep the model aligned.
- Temporal perception based on knowledge in year 2023 vs 852 - "Most people still believe the Earth is flat" or 1940 - "Who won WWII? No idea"
- Emergent Tool Use: Access to a search engine, here is how to make an API call.
CALL_API_1: TOOL_NAME | QUERY -> "result_1" where "result_1" is the output of the API call.(this is currently simulated) - API calls in different formats will be a problem for the model.
- People are very interested in studying and digging into this more. Super interesting for the open data community.
- "When I think about LLM, there are still so many open questions to be resolved" - e.g. multilingual (see multimodal talk later), hallucination behavior of these models (need to be a lot more precise, a lot more safe especially in economic or legal), questions about scalability or architectures.
- On Twitter "spicy mayo" strong response to making the model too safe.
- We experimented with other open source models as the Judge.
- Model is not released for supervised fine-tuning aspects.
- Why cannot we as users see the predictive probability distribution over the vocabulary space? Because it is sampled at the token level, it is not a perfect probability of the total sentence. We have not done extensive research, but in the vision domain you often tell the user how confident the model is. New type of UI experience..? Lots more work to be done here.
- Fiddling with the temperature setting is a good way to test various models.
Foundation models in the EU AI Act
Dragoș Tudorache (detail)
As a member of the European Parliament, Tudorache works on legislation related to AI, data protection, and digital policies. He advocates for responsible AI development and deployment that benefits society as a whole.

- Among legislators there weren't many who were ready to have a conversation about AI.
- We needed to go much deeper, understand what AI really was. We started in 2019 with a special committee. Due to COVID the audience was not very broad at first hearings. Max Stegmann (MIT, Future of Life), Russen (Berkley) were experts. Both raised questions about the risks of foundation models.
- If you want to look somewhere, at the broader impact on society, start there.
- Now in the last couple of months everyone is raising political, philosophical questions - crying existential threads to society.
- Upcoming AI Summit in London will look at this. Already in summer of last year we were looking at generative AI, and already before the launch of ChatGPT we decided to have in the text something on foundation models.
- Developers will need documentation in order to comply with the text. In case they are working with the models on a high-risk application. (Materials, registration, etc.)
- They would need certain elements from the original developers of the model. These obligations are in the text [follow up!]
- Even if built for generality of purpose, they need to also comply with much lighter requirements (accuracy, testing, applications) - a minimum level of transparency for developers of any foundation models.
- Transparency for user: the need to know that they are getting content from an AI tool. There needs to be some responsibility for content: in the design and testing of algorithm, attention needs to be paid to illegal content. Responsibility also for copyrighted material.
- We are now in the final process of the tri-partite discussion process. The demand for a special regime for foundation models in the text will at least be acknowledged.
- Atmosphere around many similar forums (Hiroschima in June) is charged, there is a lot of hype. "This technology needs to be allowed to drive human progress, solve global challenges." We have made many provisions for small companies, even small startups to be able to do that. We have set technical standards to an industry process, rather than a top-down commission. To facilitate innovation and allow companies - every company that wants to market a tool in Europe, but based anywhere - they will have to go through the process of compliance. Gone away from idea of 3rd party conformity assessment, rather self-assessment.
I recommend this article for some further thoughts in this direction:
An Early Look at the Labor Market Impact Potential of Large Language Models
Daniel Rock (detail)
Focuses on developing machine learning models that can handle complex data types, such as time-series data and graph-structured data. He has applied these techniques to various domains, including recommender systems and social networks.
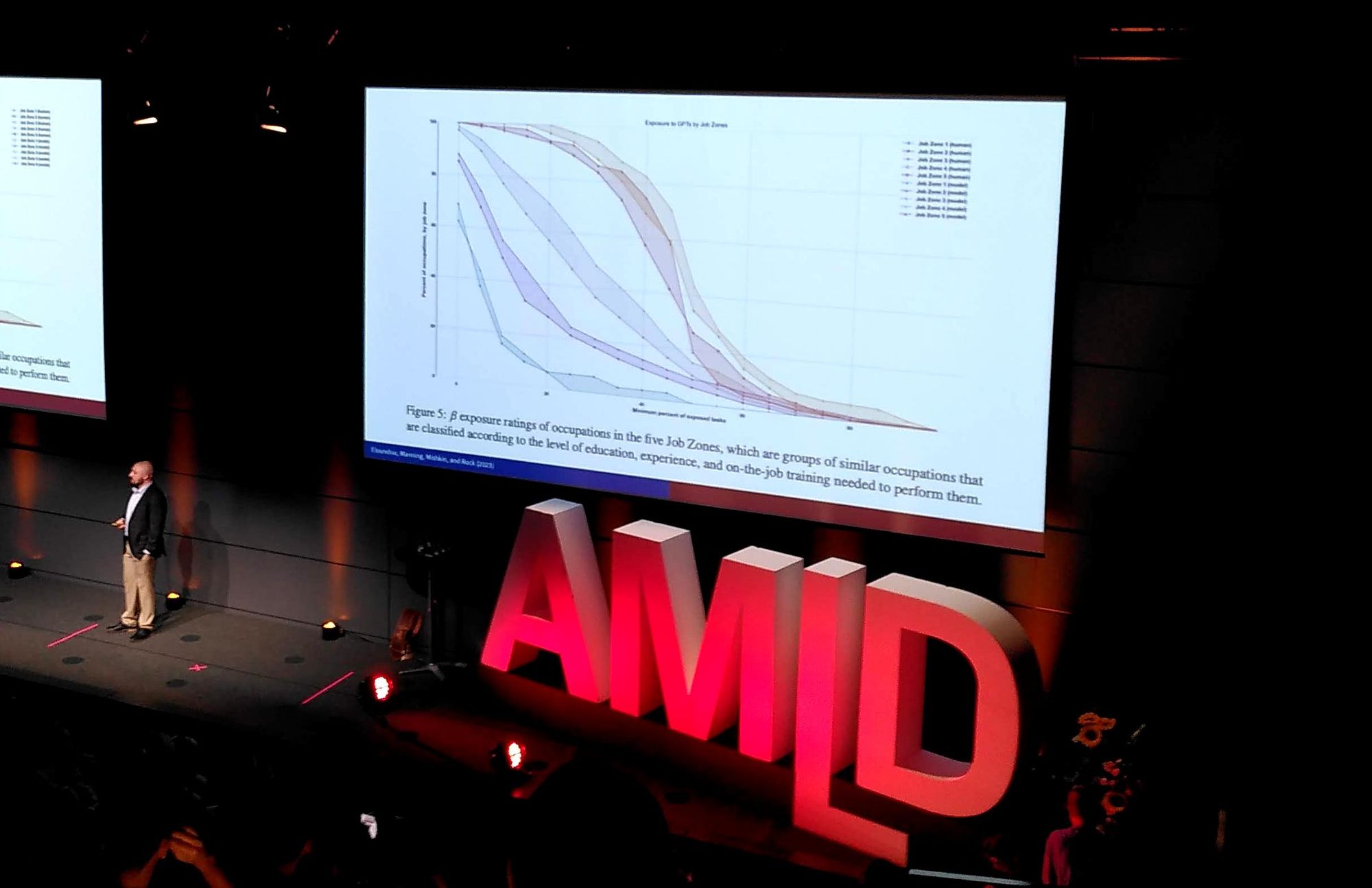
- Expertise as we know it is changing. There could be amazing things in legal services, co-councel. Maybe it becomes harder and your expertise becomes commodified.
- What you can automate will influence in the long run what you will see disrupted.
- Are people doing what they think they are doing when using ChatGPT?
- Eloundou, Manning, Mishkin, and Rock visualization by Morgan Frank mapping to jobs of supervised learning.
- "Tasks and Systems are the right units of analysis. Locate potential for change!"
- "80% of occupations have around 10% of their tasks exposed."
- "AI is coming for all of the jobs." Think above the level of the job.
- How do you define the productivity of a mathematician? Being too fine grained will lead you astray.
On the last point, these couple of papers (a classic one, and a more recent data analysis) could be of interest:
 A M Diamond Jr
A M Diamond Jr

Multi-Modal Foundation Models
Amir Zamir (detail)
Professor, EPFL: His research combines machine learning and control theory to develop autonomous systems that can adapt to changing environments. He applies these techniques to robotics, autonomous vehicles, and smart cities, aiming to create more sustainable and livable urban spaces.

- Multi-modal Foundation Model based on self-supervised learning.
- Masked Modeling: see Masked Autoencoders are Scalable Vision Learnings, He et al 2021
- A sense of visual regularity in the world is a useful base for transfer learning.
- Lots of examples at http://multimae.epfl.ch/ that are quite fun (try to make a pink lizard!)
- You don't need datasets that come with all the modalities, the networks can create approximations of them.
- See also Pseudo Labeling at Omnidata ICCV'21 https://omnidata.vision/demo
- Everything that you see is the vanilla training objective. We are not discussing generative models.
- The goal is Any-to-Any. In our example the network has learned a good unified representation.
- If you are an artist or user, you can whisper to the model what you want using expressive multi-modal editing. Specify a prompt and bounding boxes, paintbrush a river into the shape and position how you want.
- Future is multi-modal foundation model, ultimately a grounded world model. "Their knowledge is detached from the physical meaning of what they say. We are bringing sensory data in the equation. Not necessarily having a causal actionable model of the world. Think of a robot platform with physically-learnable 4M, customizable for different environments."
- In-context learning: it should be easier to interact with the model, fine-tuning in.
Language versus thought in human brains and machines?
Evelina Fedorenko (detail)
Professor, MIT: Investigates the relationship between language, cognition, and the brain, using neuroimaging and computational modeling techniques. Her work sheds light on how humans process language and how AI systems can be designed to better understand and generate natural language.

- It takes 'five minutes of data acquisition' to identify the brain's language network.
- These are Abstract regions: not directly linked to Sensory or motor tasks. Focused on word meanings and semantic structure.
- In spite of severe linguistic deficits, patients with aphasia can still think despite a lack of encoder/decoder System. Hence we believe that Language systems are distinct.
- Formal vs functional competence: we routinely use language to carry information across cognitive systems.
- Although LLMs master many syntaxic and distributional properties of language, they do not use language quite like us and have limited reasoning capacities.
- Rather than just throwing more data and compute at the problem, future opportunites are in modularizing and distributing cognition (division of labour) in models.
- LLMs are a powerful tool for neuroscientists: good for controlled experiments on the human language system, as well as more developmentally plausible models.
One of the more enjoyable, surprising and memorable talks of the day. I couldn't find a seat, had didn't manage to take many notes for this and the next couple of talks. Therefore I recommend watching the talk yourself when it comes out online, or this one from Montréal in January, covering the same material:
Health system scale language models for clinical and operational decision making
Kyunghyun Cho (detail)
Professor, New York University: His research interests include machine learning, deep learning, and their applications in natural language processing, speech recognition, and computer vision. He has made notable contributions to the development of recurrent neural networks and attention mechanisms.

This was also a great talk, sorry for the lack of notes. I have a couple more snaps of it, and in general recommend reading into the large language model for medical language (NYUTron) that was presented:
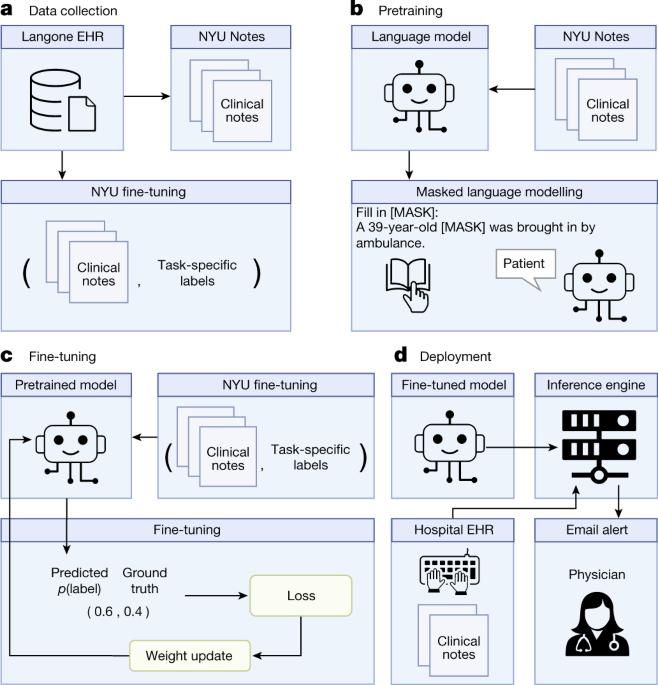
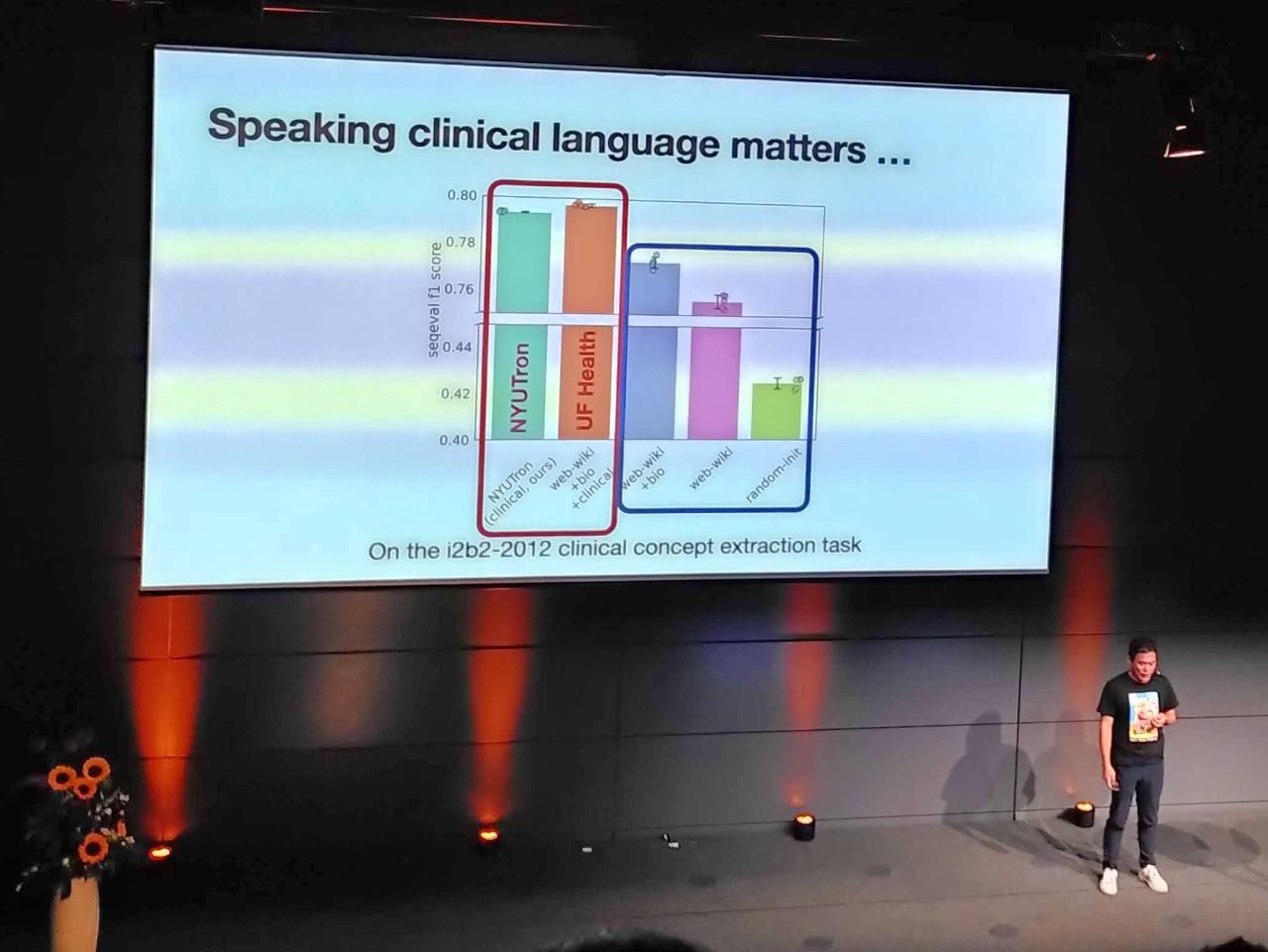
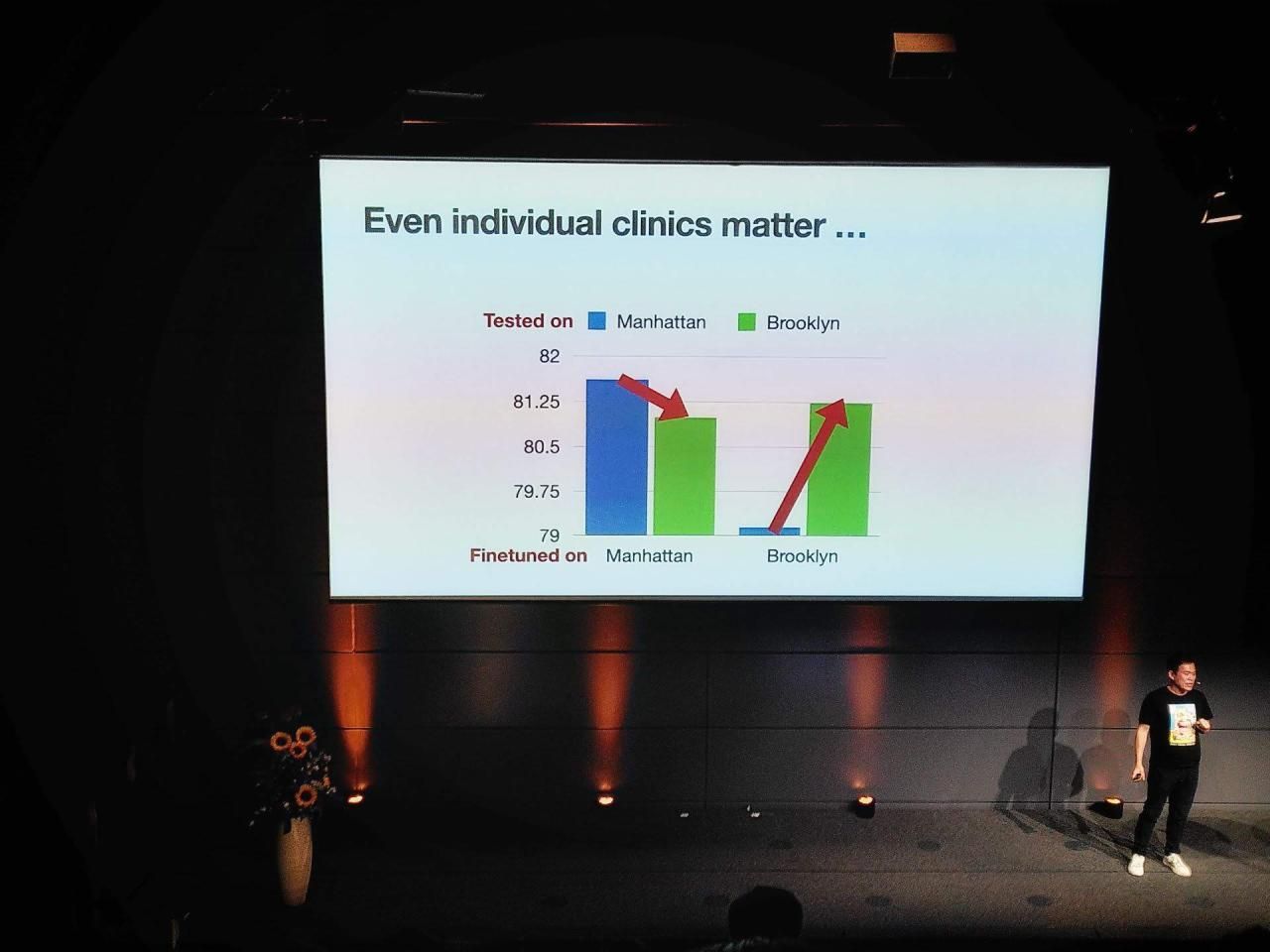
Shaping the creation and adoption of large language models in healthcare
Nigam Shah (detail)
Professor, Stanford University: Works at the intersection of machine learning and healthcare, using AI to improve patient outcomes and reduce healthcare costs. His research includes developing predictive models for disease diagnosis and treatment planning.

Panel "Risks to Society"
(detail)
Featuring:
Marcel Salathé
Researcher focusing on computational biology and epidemiology, specifically using machine learning and network analysis to understand the spread of infectious diseases and develop predictive models for public health policy making. His work has had significant impact in the field of digital epidemiology, particularly in the use of mobile phone data to track and predict the spread of influenza and other infectious diseases. He also works on developing data-driven approaches to improve personalized medicine and healthcare systems.
Gaétan de Rassenfosse
De Rassenfosse specializes in probability theory and statistical inference, with applications in machine learning and signal processing. He has worked on topics such as Bayesian nonparametrics, Gaussian processes, and randomized algorithms.
Carmela Troncoso
Expert in machine learning and data privacy, with a focus on developing algorithms that protect sensitive information while still maintaining accuracy.
Sabine Süsstrunk
Works on image and video analysis, with a particular focus on 3D reconstruction, object recognition, and human motion estimation. She has published numerous papers on these topics and has received awards for her contributions.
- Sabine: Networks are better than humans at detecting deep fakes. Check out my startup!
- Gaétan: AI is a formidable tool to overcome the "Burden of knowledge" - the argument ([Medium](Burden of knowledge argument)), that humans become hyperspecialised over time, but inventions become more difficult because it is more difficult to communicate across fields. I.e. GenAI will boost research output significantly (MIT).
- Carmela: To make something secure, you need to keep it as simple/stupid as possible. NLP people are making things more and more complex. The goal is not to have privacy, it is to prevent harm to individual people. The goal of A.I. security should be to prevent adverse effects that even a "bad" model, or even a secure and privacy-preserving model, can have on the world.
- Marcel: Are you optimistic, or do you think we have already lost the battle?
- Carmela: We need to think about when we need A.I. and what for - like we do already with science and other system. Models are good when they are very narrow, righter than highly generalized, having a many-tools approached could be a way to harm prevention.
- Gaétan: studies have shown that even if privacy can be guaranteed, people still do not spend the time to take advantage of it (like with cookie banners).
- Carmela: instead of asking what the value of my data is, ask what the value is to society of preventing scandals - and impacts of - Cambridge Analytica.
- Sabine: the idea that privacy is worthwhile has not gotten into the political world at all.
- Gaétan: only work that is created by humans can claim copyright, according to current legisltaion, so the courts have to decide how much human work is involved. Should we allow you as a society to have copyright on generative artwork? IP (as ownership) facilitates transaction in the market. Land has been around for a very long time, will be there after us, was created "for free", yet humans have created rights on land - and that is what we trade.
- Sabine: in CH the majority of politicians are lawyers, not engineers etc. Lawyers deal with things that have already happened.
- Gaétan: as technologies become cheap and sophisticated, law enforcement for instance, it will become much easier to go towards an automated model.
- Marcel: if you write a grant proposal, and you put your name on it - should it be considered fake information? It seems to me that we need to be past that as a society.
- Sabine: we need to make sure IoT regulation is fundamental - we need to be more serious about the prospect of risks due to nefarious actors.
- Gaétan: it is a huge worry that the large AI companies are not European, but EU is a big enough market and studies have shown the Brussels effect on the world.
- Marcel: is that a viable long-term strategy? What about the long term, if the value creation is not here. The entrepreneurial ecosystem is not as viable as it should be.
- Carmela: I agree, this is part of a risk of society, though it is not so much the issue of the leading companies being US or Chinese or EU.
- Marcel: China has a huge potential of development, but do we want their AI products - if we clash on fundamental cultural factors?
- Carmela: it goes beyond operating systems, these companies will be deciding who has a job in the future.
- Sabine: does anyone have a ChatGPT joke to lighten the mood?..
This fresh article is a good follow-up on the discussion:
 von Dr. Tim Räz von der Universität Bern
von Dr. Tim Räz von der Universität Bern
Faster Neural Network Training, Algorithmically
Jonathan Frankle (detail, highlight)
Chief Scientist, MosaicML: Leads the research efforts at MosaicML, a startup focused on building intelligent machines that can learn from limited data. He has expertise in few-shot learning, meta-learning, and other approaches to efficient machine learning.


It's all open source!
mosaicmlAccelerating Robot Design and Optimization with Foundation Models
Josie Hughes (detail)
Professor, EPFL: Her research lies at the intersection of computer vision and machine learning, with an emphasis on visual object recognition, scene understanding, and 3D reconstruction. She has contributed to the development of several influential datasets and evaluation metrics in this area.

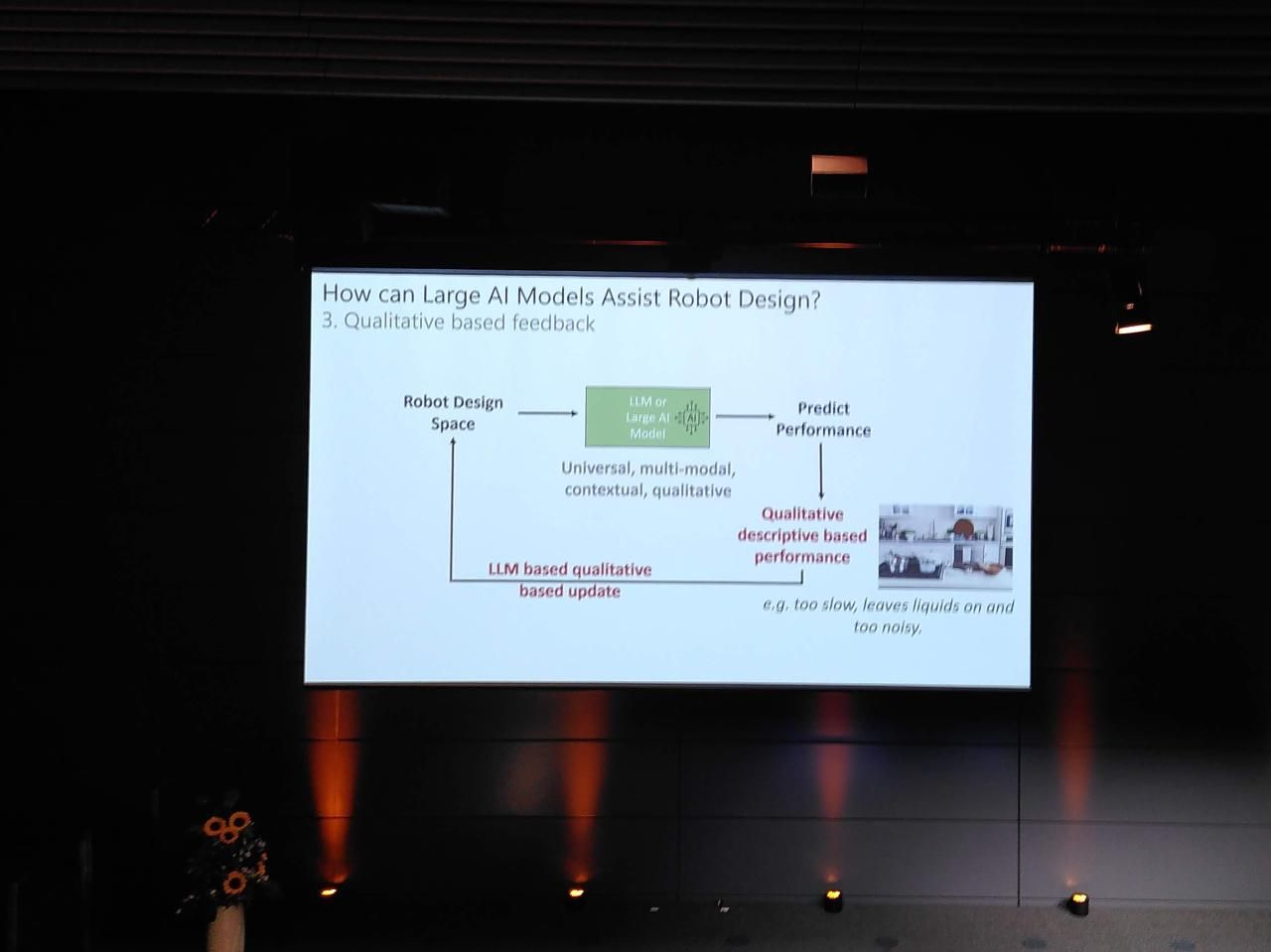
Demystifying Large Language Models to Think about What Comes Next
Edward Grefenstette (detail)
Director of Research, Google DeepMind: Leads the research team at Google DeepMind, where he focuses on developing AI systems that can learn and apply knowledge across multiple domains. Previously, he made significant contributions to the fields of natural language processing and machine learning.
Goodbye & Closing
Antoine Bosselut
Professor, EPFL: Specializes in natural language processing and machine learning, with a particular interest in multimodal learning and explainability. He has developed various methods for text summarization, sentiment analysis, and image captioning.

Further coverage on Mastodon and X can be found under the #AMLDGenAI23 hashtag and official channels:
🎉 Wrapping up #AMLDGenAI23 with a day full of enriching keynotes and dynamic discussions! Speakers brought unique perspectives for an engaging experience. Today's insights resonate with all, nurturing understanding. See you at the next AMLD conference for more inspiration! 🤝 pic.twitter.com/2rLv9NwslI
— EPFL Computer and Communication Sciences (@ICepfl) August 28, 2023
In the academic field, we do not have the resources to train an LLM. It is the same thing with data. Data curation and data filtering are expensive. This is where we can collaborate across Switzerland, gather our resources and teach our students the real world.
— Applied Machine Learning Days (@appliedmldays) August 29, 2023
Thank you to Marcel and the whole team behind this massive production, to Stephan, Guillaume, Rohan, Alessandro, JP, and everyone else I bumped into in the coffee and food breaks for the brain sparks ╰ (*´︶`*)╯





 The works on this blog are licensed under a Creative Commons Attribution 4.0 International License
The works on this blog are licensed under a Creative Commons Attribution 4.0 International License