104 #opensource #ai
Quick and raw notes from the Open Source AI Conference, organized by CH Open and BFH/IPST on May 7. This is a research area for the University, clarifying the still somewhat volatile definition along with recommendations for the public sector. See also my Part II from the workshops.

Oh and, by the way, Maintainer Month is going on as well right now, a chance to contribute some documentation or pen testing to your favorite FOSS:

Just avoid AI slop in your patches, plz:

There was related discussion at yesterday's TRANSFORM event, I invite you to browse the posts from my live coverage:
Getting back to the Wednesday afternoon conference, here is what we heard:
13:00 Welcome
Matthias Stürmer and Markus Danhel
- The intro makes it clear that we are in risky, murky waters, and urgently need to respond to the topic - but actually everyone in the room knows this.
- What I would like to hear, is how do CH Open and Red Hat support a community of practice, besides today's event? How many member organisations are AI-ready, and run a sovereign data automation pipeline? What standards and legal guidelines exist? Hopefully this will be made clearer in the near future, all eyes on the board.
13:15 AI is not a dream, it is a choice
Andy Fitze, Co-Founder Managing Partner Swiss Cognitive


- We predicted much of what is happening, the rise of interest in automation, the war of chips.
- Agent AI will be understood and adopted by 80% of C-class by the end of this year.
- There will be no reason to discuss security or data protection. It will be "solved" by integrations into the multi-agent pipeline.
- Today we train people to understand technology, tomorrow we will build technology to understand people.
- We need to think about the bigger scale of AI competitiveness, every use case is a small step forward.
- Leadership! . . .
13:50 Confidential Compute AI meets digital sovereignty
Thomas Taroni, Executive Chairman, Phoenix Technologies AG

- We need to trust our AI a lot just to book a table at the restaurant. Your email credit card calendar: ready to give it up to the autopilot?
- With process and people power earlier ventures were moved forward. Now we use innovation as a motor in the same way. Without (open source) sovereignty there is no real innovation, we are progressing on borrowed time.
- Hallucinations? The data that we use to correct them are worth protecting at any cost. On the GPU the datasets are available for milliseconds, unencrypted. For a public cloud it is irresponsible (grob fahrlässig) to put information out of control.
- We developed our own cloud. If I knew all the things that were necessary for this, including our own power supply and AI cluster and cluster design, we would not have done it. It's incredible to see all these moving parts and people coming together in Switzerland. We created the Switch edu-cloud based on the same architecture, and hope to win more federal cloud contracts.
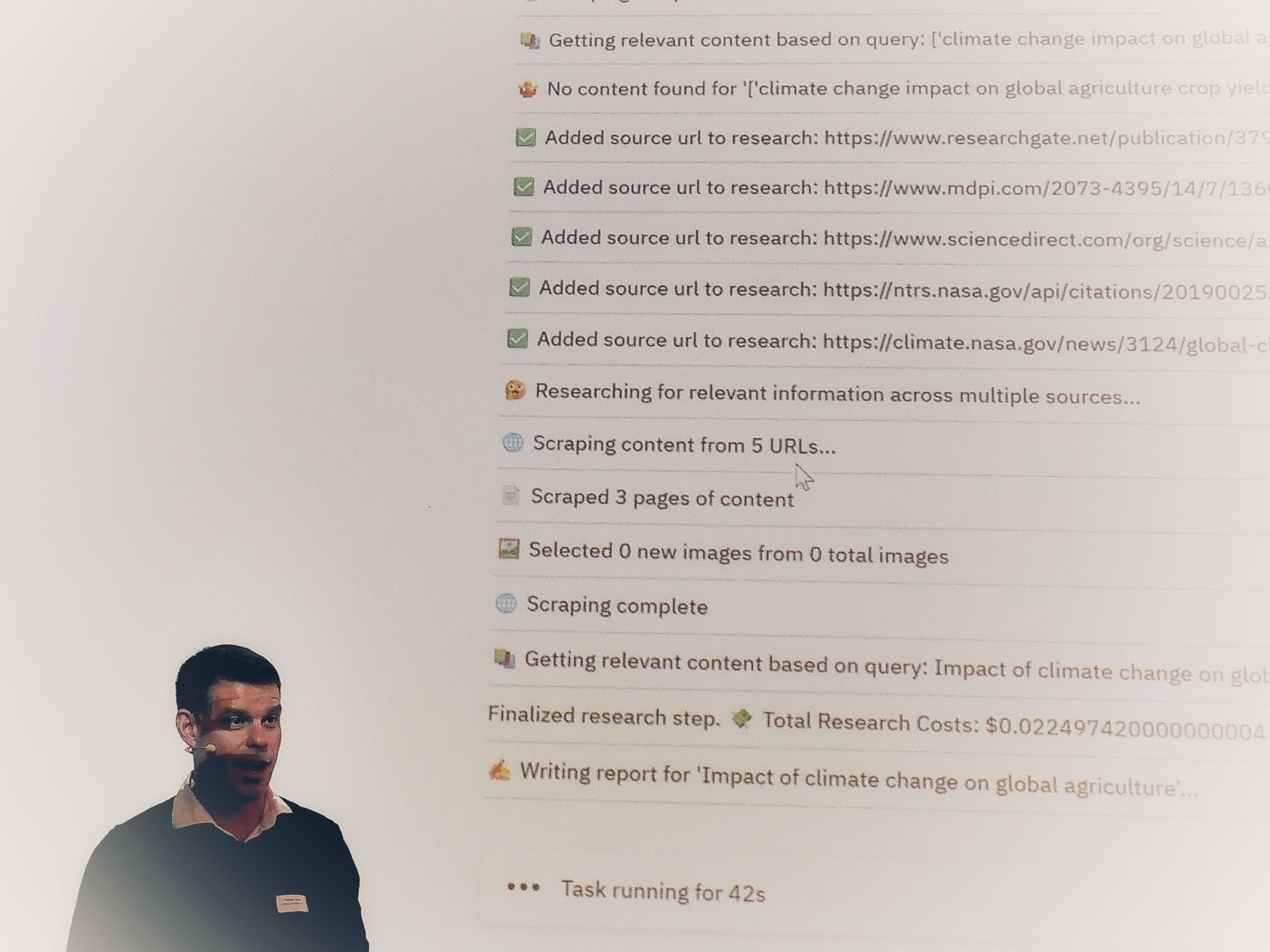
- Can you imagine having your whole org team made up of agents? We're not quite there yet, but think about it. A year ago, I pulled a coder agent into my IDE, the result was sh*t. When I code, I need transparency and to see what steps the agent is taking to arrive at a result.
- Shows a demo of an agent generating a report on global agriculture, where the sources are mostly well known international and US organisations. Even if we can see the sources, how does the agent help us check their authenticity and bias?
- The code demo is a textbook case of a factorial program, which defaults to Python, and makes suggestions of unsurprising use cases. Why this language, why this code, why these bugs and patterns? The creativity and elegance of programming and logical thought seems extremely shallow. The Agentic documentation spews out a bunch of very verbose overview followed by minimal bullet points.
- DeepSeek is not sovereign, and the biases implicit in this AI model are not shown anywhere. I don't see any model cards or semantic references in the log.
- The future for kvant looks bright.
14:20 Coffee break
- I spoke to several fellow participants. We agreed that so far there has been yet little mention of the issues creative people, coders and citizens are facing. We are determined to stick around and hope to hear more practical advice next.
- Have you talked about job security and AI with your local tech union?

14:40 The Impact of DeepSeek-R1 on Open Source AI and the Rise of Large Reasoning Models
Lewis Tunstall, Hugging Face

- OpenAI discovered the scaling laws which allowed predictable returns, through smaller scale experiments, using benchmarks and a series of measurements to understand the loss while trying to refine a model. See https://openai.com/index/gps-4-research
- But it seems that, as with Moore, the laws of physics get in the way. NVIDIA can only produce so many chips. Epoch AI has assumed that if we will invest hundreds of billions of dollars, we will scale up.
- There are crazy stories around the past deprecation of GPT-4.5, probably the largest model ever deployed in public, involving replication along multiple data centers.
- E.g. the PyTorch sum function apparently had a bug, just as an example of the issue at scale. People wonder if tech companies can keep up their progress.
- Auto regressive decoding: feed in text, let the Transformer architecture use a fixed amount of compute no matter what the problem. These models have no way to determine how complex the question is. Is o1 and DeepSeek an actually new approach to machine learning, or just a hack (aka user experience paradigm) designed to bust benchmarks?
- The science was available for a year, nobody noticed, until some great engineering and new data was applied to prove the hunch. Basically, it sounds like the Wissenschaft behind all this is still emerging, and open source is leading to a more chaotic and disruptive development. Keep your eyes on arXiv.
- Assuming it's not, how has it changed the practice of prompt engineering. To what extent do system prompts allow the engineering of faster reasoning pipelines? To be prompt-researched later.

- Reinforcement learning with verifiable rewards (RLVR) have a surprising feature that token lengths increase during training from a couple of hundred to up to 10000.
- The *aha!* moments are very eery and akin to human insights. The Distill models were a really good gift to the community. But how do we do this ourselves, adapt it to our use case and datasets? Can we train fully open (weights and code) models? Yes, we can.
- Hugging Face started with mathematics, as it's easier to test. You start with a source of hard products, like the IMO.
- We used a library to verify equivalence between mathematical expression. (Mathematicians, sorry, your work is also just open data for the choppAIng block now!)
- OlympicCode 7b runs on your phone and does very well on the AI math olympiad, heralding a new age of AI tooling.
- It is very slow to generate the models, we ran into a lot of scaling issues involving GPU management.
- Code verifiability crisis (skipped)
- DeepSeek-R1 had a huge impact on open AI: better tools for reinforcement learning, explosion of interest in reusing data sets. Just search "reasoning" in HF datasets.
- How far can you compress? Phi-4 recently released by Microsoft has very impressive performance.
- Where is the moat in terms of the ability of open source to truly close the gap in all sectors? It sounds to me like compute capability, open or closed is really the determining factor in the AI wars - instead of getting too wrapped up in their daily battles, we should focus on the transformational changes and ethically tolerable and professionally defensible use cases.

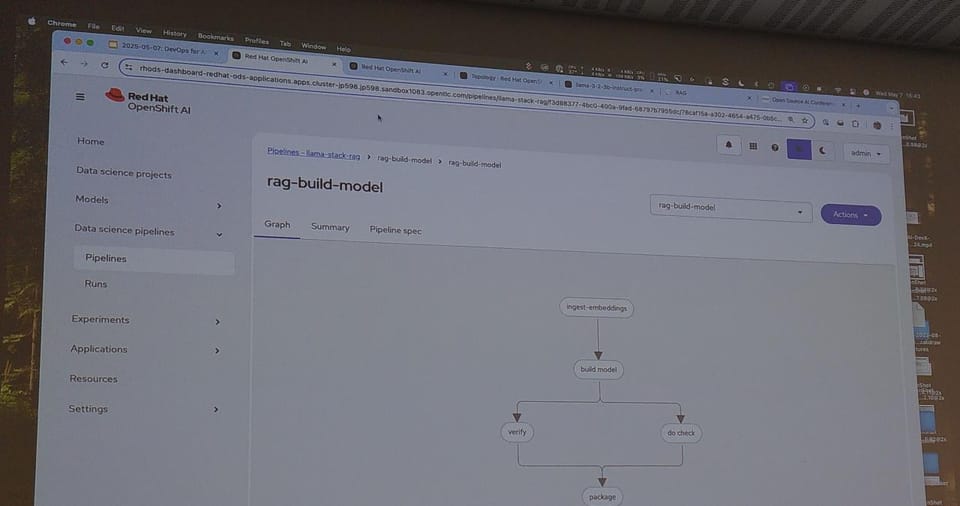
15:15 DevOps for AI: Bring AI to the data, not the data to AI
Aarno Aukia, VSHN and Manuel Schindler, DevX Team, Red Hat

- DevOps have come of age and we are rocking it.
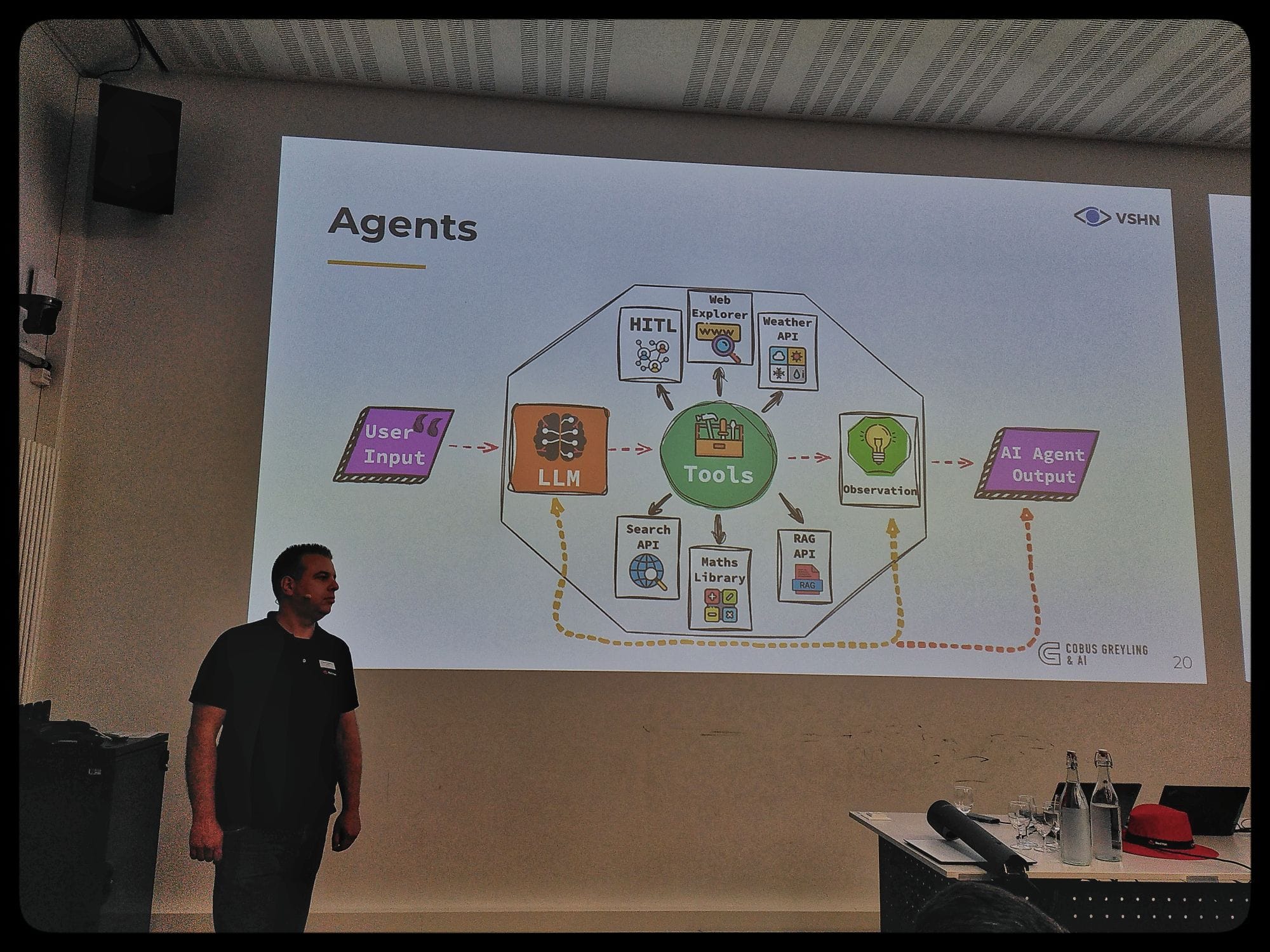
- Using RAG the LLM is part of the software workflow.
- Agents are a useful software construct. Like they will bring lots of different info sources together.
- Arno seems still a bit confusing the open weight and open source terms, making only the distinction in what runs where. The infra guys want to run your APIs, but not train your model.
- Ollama is what we use in development. KubeFlow with KServe for production.
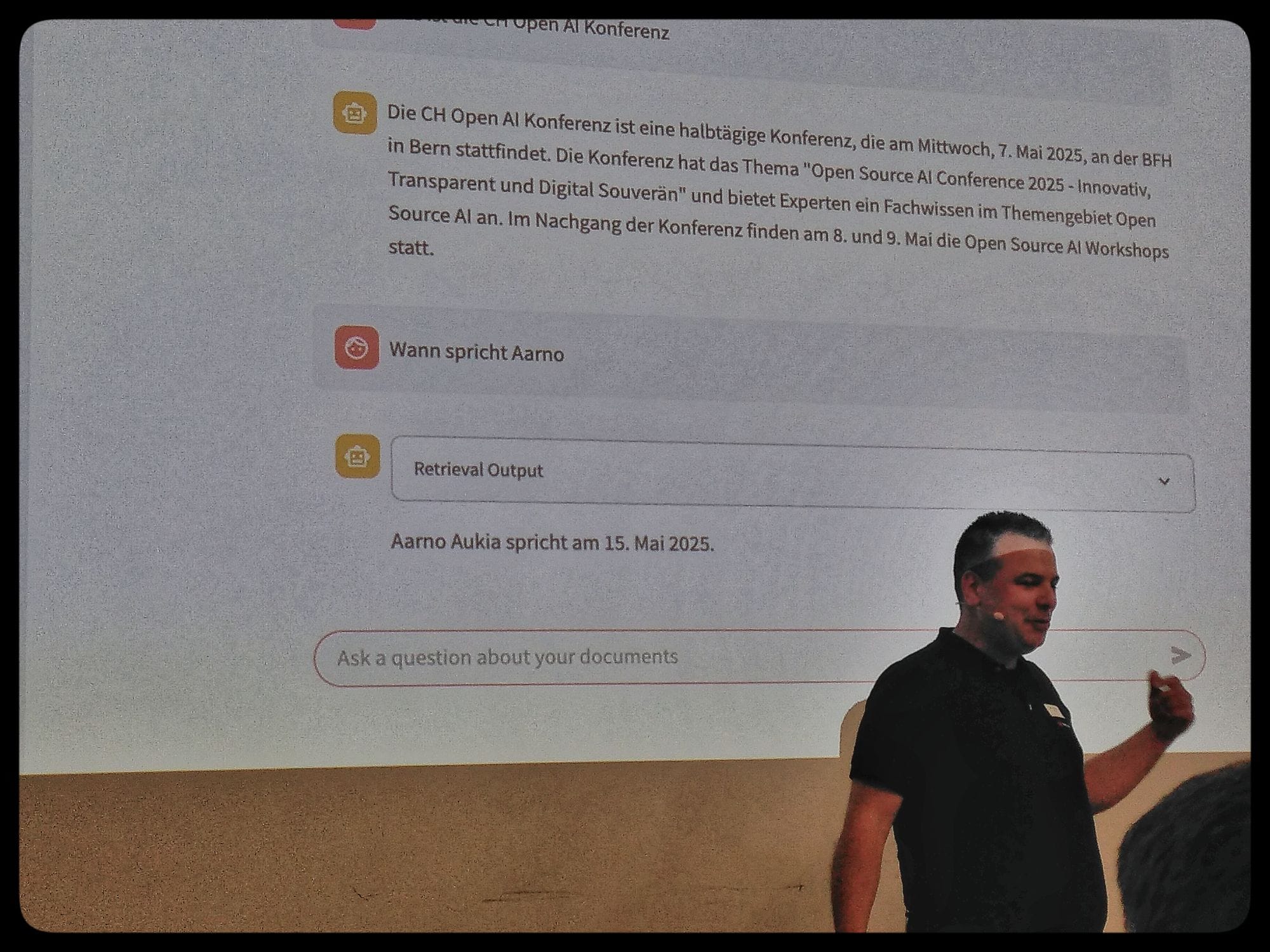
- Demo of the OpenShift workbench with Red Hat.
15:45 Coffee break
- I had to take off, family duty calls. Will try to fill in the gaps l8r.
16:05 Panel Discussion
Innovation, Transparency and Digital Sovereignty Erica Dubach, Digital Transformation and ICT Steering (DTI) at Swiss Federal Chancellery (Bundeskanzlei) Jacqueline Kucera, Head of the Parliamentary Library, Research, Data (The Swiss Parliament) Ornella Vaccarelli, Lead Scientist at SCAI - Swiss Centre for Augmented Intelligence



Thanks very much to the team, speakers, sponsors! 🫶
I'll make good use of the take-aways from today & looking forward to the workshops tomorrow and Friday!





 The works on this blog are licensed under a Creative Commons Attribution 4.0 International License
The works on this blog are licensed under a Creative Commons Attribution 4.0 International License