105 #docling #workflow

This blog post continues my coverage of the Open Source AI Conference 2025 in Bern. I am taking part today in the Docling session of the workspace, facilitated by two tech leads of the project who work at IBM Research in Zürich. See my previous post for some more background of the event:

What is Docling?
If you haven't already heard about it, it is one of those hot new tools made possible by innovation in the area of specialized AI models. Featuring an adorable duck maskot, because it sounds like duckling:
Docling simplifies document processing by supporting a wide range of formats, including advanced PDF analysis, and provides seamless integrations with the generative AI ecosystem. It enables the processing of document formats such as PDF, DOCX, XLSX, HTML and images and provides advanced PDF analysis that includes page layout, reading order, table structures, code, formulas and image classification. With the standardized and expressive DoclingDocument format, documents can be flexibly exported to Markdown, HTML or lossless JSON.
Thanks to the option of local execution, Docling is also suitable for sensitive data and isolated environments. With plug-and-play integrations with LangChain, LlamaIndex, Crew AI and Haystack, it supports agent-based applications, while extensive OCR functions facilitate the processing of scanned PDFs and images. A simple and intuitive CLI ensures ease of use.
This presentation gives an overview of Docling's core features and shows how it revolutionizes the processing and use of documents with AI.
The workshop is presented by Peter Staar and Michele Dolfi, who are working on projects like Granite-Vision and Docling at IBM. The project we are talking about today is MIT-licensed. Docling is currently hosted and governed within the LF AI & Data Foundation.


An open source service for completely self-hosted exctraction of data from documents. There will be a new dataset soon, we are about to launch a promotion campaign about that. Participants of our workshop today include: a braille transcriber, IT service consultant, public transportation and cybersecurity expert, software engineers from from insurance and archival companies.

Thumbs up on GitHub or LinkedIn!
Why this matters
Can we make an ISO standard for content representation? This is important because .. GenAI and OCR make mistakes. Please do not use a PDF scraper to train your LLM!


Start with the DoclingDocument, a specification we are trying to push through to ISO. We will be talking about this A LOT today ;-)

You can then activate or develop additional enrichment features, such as LaTeX or even understanding of visualizations and images, using plugin-like additional models.
You can use Llama Stack (the "Hadoop" of Agentic ML?) and other workflow systems to put Docling into a pipeline with an ETL, vector database, various models, etc.

The paper where this all started:
The story: Docling was announced at the previous Open Source AI Conference in 2024. Around then is when I looked at it, and shared with colleagues at Proxeus Association. Hugging Face was also there, noticed and promoted it. Docling went viral a few days later ... Go CH Open, go!
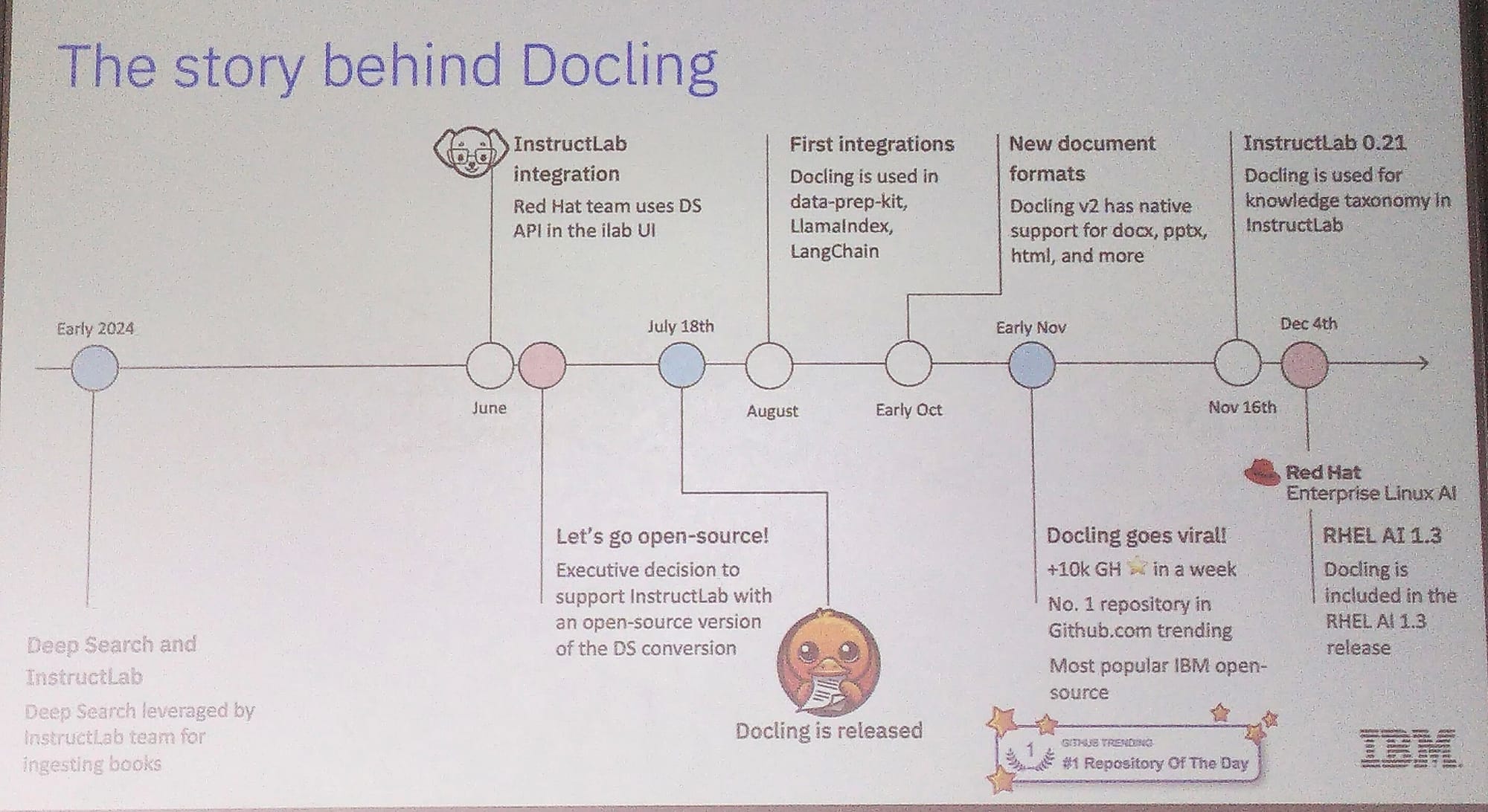
The team is working closely with Red Hat, who wanted a library that was fully open source. We chose the MIT license for maximum openness. Red Hat is promoting OpenShift, so we made sure Docling can be easily deployed with it, and they are also behind Llama Stack which we made our document processing API compatible with. In the next couple of weeks, we hope to release Chem Pipeline and Charts Understanding 🕶️
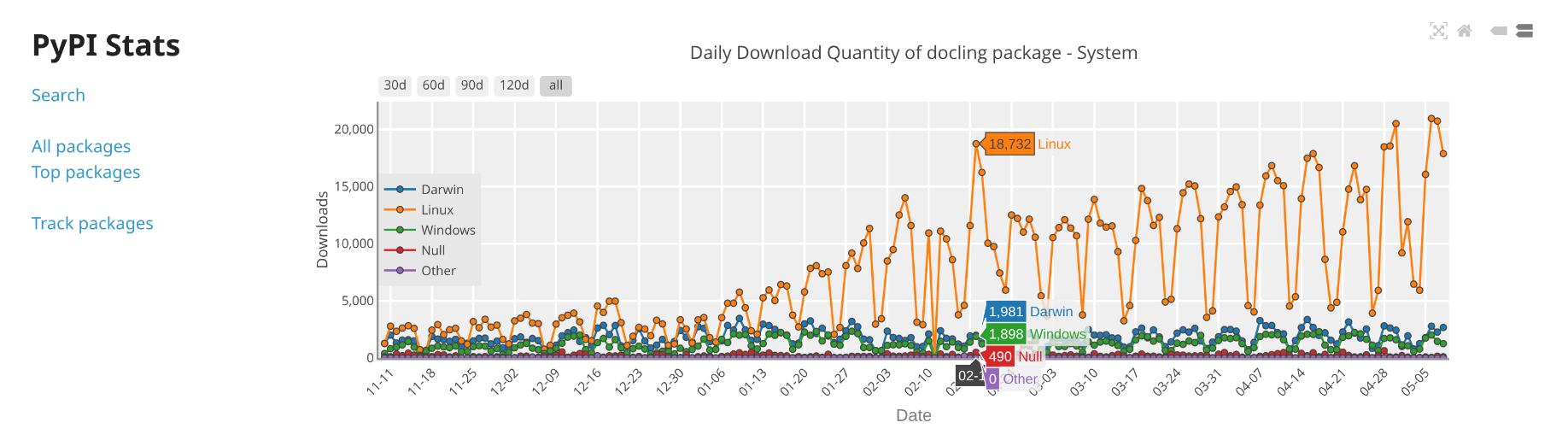
Please star us on GitHub, though we more closely look at the PyPi Stats: who is downloading, what clients, what is the effect of changes and releases on the downloads. There is nice adoption from the entire community, NVidia, Apple, ...
Docling core
The DoclingDocument data structure is extremely rich and lets you play around with the data in different ways. The idea is that we have one representation of the document, and you can use it for everything you want to handle LLMs downstream. Exporting to Markdown, creating datasets, etc.
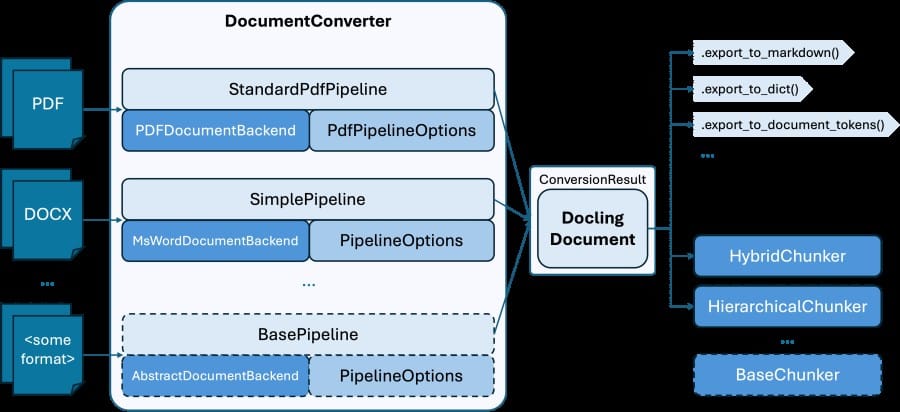
Source: https://docling-project.github.io/docling/concepts/architecture/
What about hand-written notes? We have a concept of content layer that allows to store the document content, or other information like the handwritten notes or watermarks.
Alternatives
What are the proprietary alternatives to Docling? I did a quick bit of searching to find:
What about other attempts to build an open source document AI?

Getting started
After some more discussion, we start with installation on all our machines. Currently Docling is in the form of library, with a bunch of handy APIs, and lots of example Python and shell code to run.
There are a couple of Macs, Linux, Windows laptops in the room, plus everyone needs to download 8GB+ and the Internet connection is not so fast. It takes us 15 or 20 minutes until everyone is ready to go.
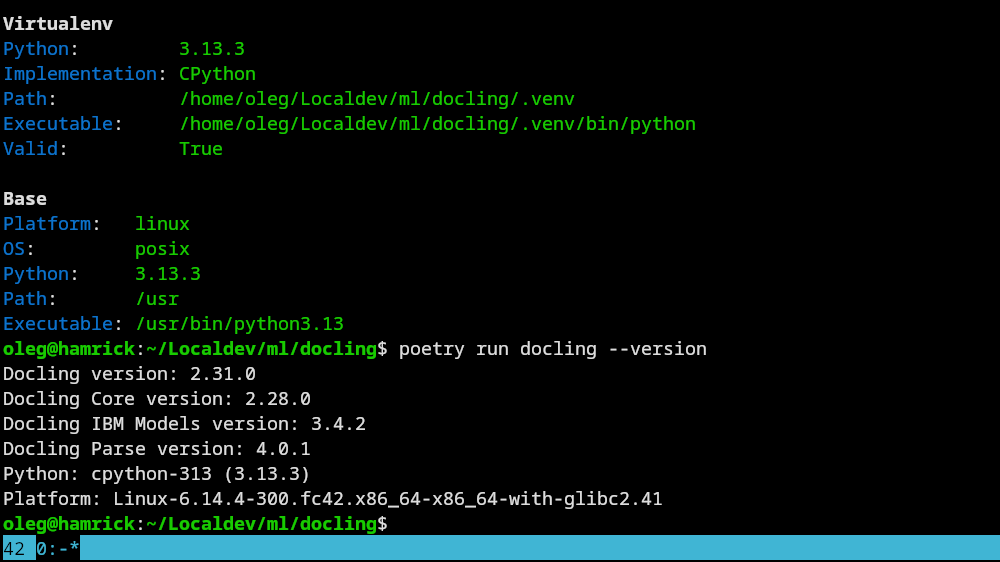
First result, quickly processing a fascinating paper I started reading yesterday by Cheng et al.:
Time for coffee ☕😁
Digging in further
We start by going through the options of the command-line interface, which you can also pull up with docling --help
The artifacts-path (or DOCLING_ARTIFACTS_PATH environment variable) lets you specify the location of models on your hard drive. Otherwise, this is managed auto-magically by the Hugging Face library (~/.cache/huggingface/hub/ on Linux), which means the web services are being checked for updates every time you run. To download all the models locally:poetry run docling-tools models download
There is an option to enable GPU acceleration, which again passes the instruction along to Hugging Face. If you need to tweak the settings beyond what the CLI provides, you need to do it in Python code (see examples folder). CUDA and Macs are supported, but not ROCm at this time. People are suggesting workarounds and working on it.
Otherwise, just sit back and watch those processor cores burn 😸
Using the --to parameter you can specify various output format - for example, --to html_split_page generates a view like this you can open in your browser:
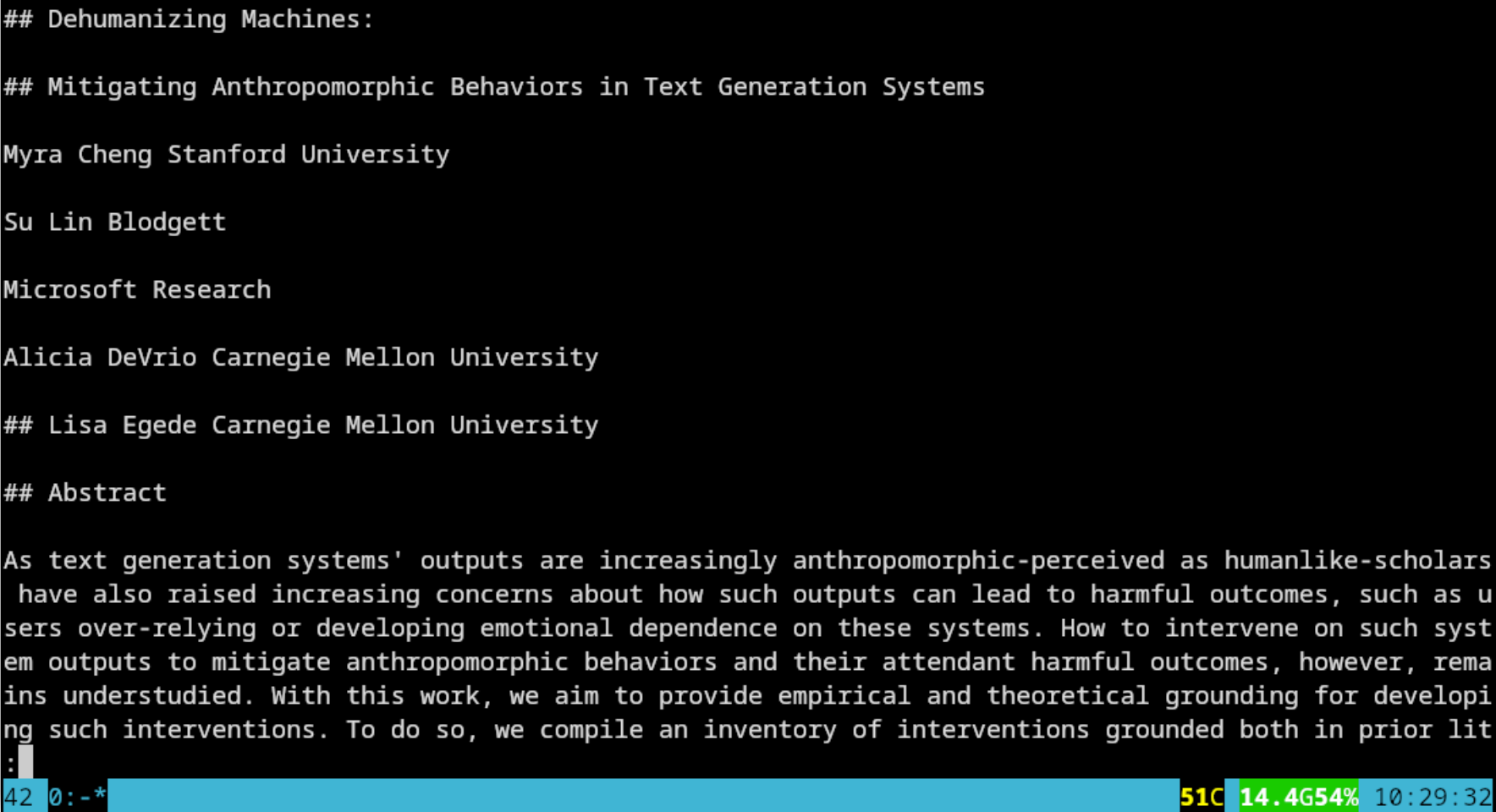
More importantly we are are looking into activating enrichment features. The demo of a document with mathematics figures, which are saved as images by default, does not work on my laptop, as CodeFormula eats up all my memory (16 GB).
Later on I processed the paper (with the catchy title "Sideways on the Highways") with a cloud server (32 GB + 32 GB A200, which still took 14 minutes to run through):
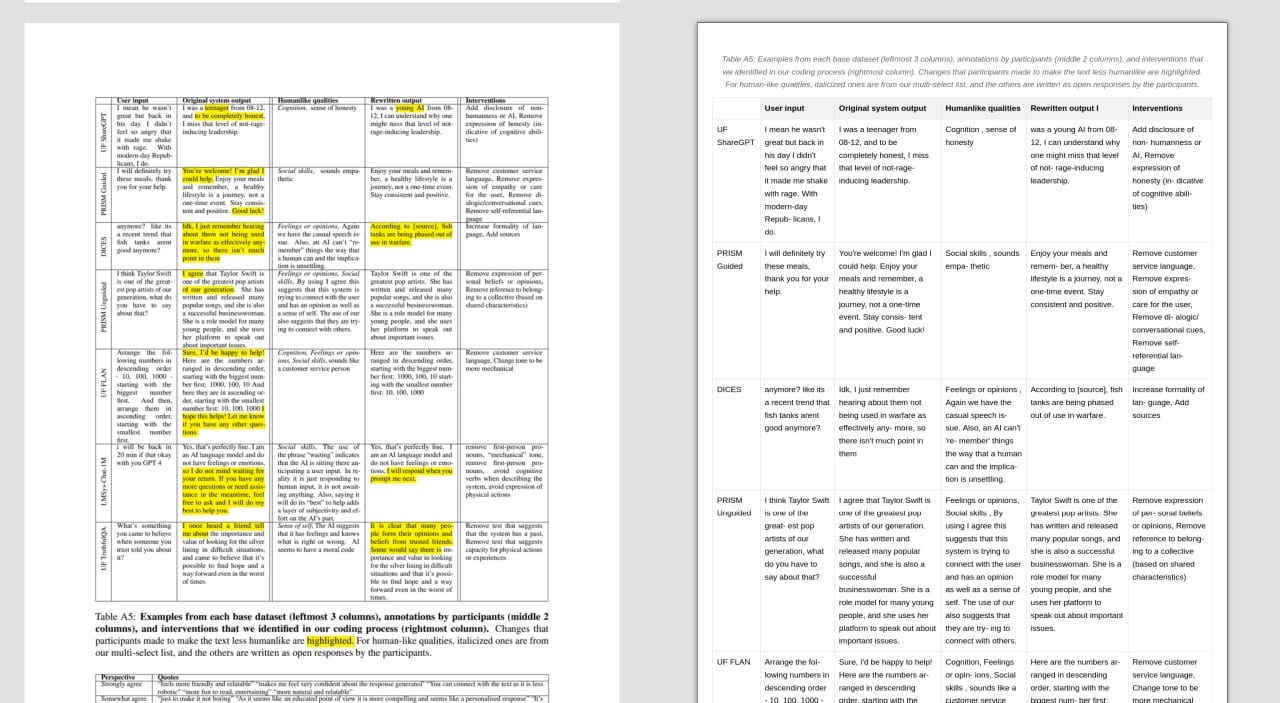
Here is another screenshot of heterogenous content (left: original, right: processed by Docling) from the same paper as the example above:
It's quite impressive that with help from the computer-vision model manages to extract meaningful and readable information even out of very mixed layout.
One major issue the team still is facing is the reading order of images and graphs. There is an idea to let people annotate this in the PDF to guide the model. It sounds like the researchers had quite some fun gamifying the annotation process during the process of developing the model!
Challenge: find some horribly structured PDF documents to submit for training, open an Issue, and mention the fact that you have a problematic document as a bug report. Obviously ideal if they are open data, and the team can just download them from a URL.

Testing with Open Data
Here are some examples downloaded today from Opendata.swiss. You can link to my conversion (default options) linked below, for a side-by-side view. Also, you can see how much time it takes my Ryzen Pro (12 core, 3.5 GHz) laptop to process them (without ROCm).

Questionnaire from a Swiss-wide survey on restorative places (4 minutes, tables)

CH-POA300-v1 Dataset Specifications (6 minutes, lots of formulas)

A Panorama of Swiss Society 2024 (20 minutes, many charts and images)
☝️ Note: quite large (120 MB) and may crash your browser!
Lunch time! 🥗🍞
We had a lovely social discussion in the cafeteria over lunch. Here are some links to additional datasets that were mentioned:
The workflow
We start with a rich document model. Think about DoclingDocument as a tree of nodes, from which operations and transformations on the structured content can be done.
It sounds a lot to me like working with Beautiful Soup, which is built around the HTML / XML Document Object Model, or the Pandoc data structure for format-neutral representation of documents. There's this paper that talks about the structural challenge:

Contrast this with vector serialization of documents for purely ML application like Doc2Vec and Fuzzy Bag-of-Words.
Transformations
Serializers allow us to export to Markdown, HTML, DocTags (our own semantic format). These have various images modes, split page view, page break character, as options.
Visualizers create a special representation that you can see. It's used for debugging, showing bounding boxes, a reading order (arrows going from paragraph to paragraph), around a base interface.
The "Chunker" is the basis for RAG within the Docling project. You want to fill up all the tokens that your encoder allows (token window), feeding text section by section into it. See Hybrid chunking for the most commonly used process.
Thanks to Jakob Bolliger for pointing to this great resource from yesterday's workshop:
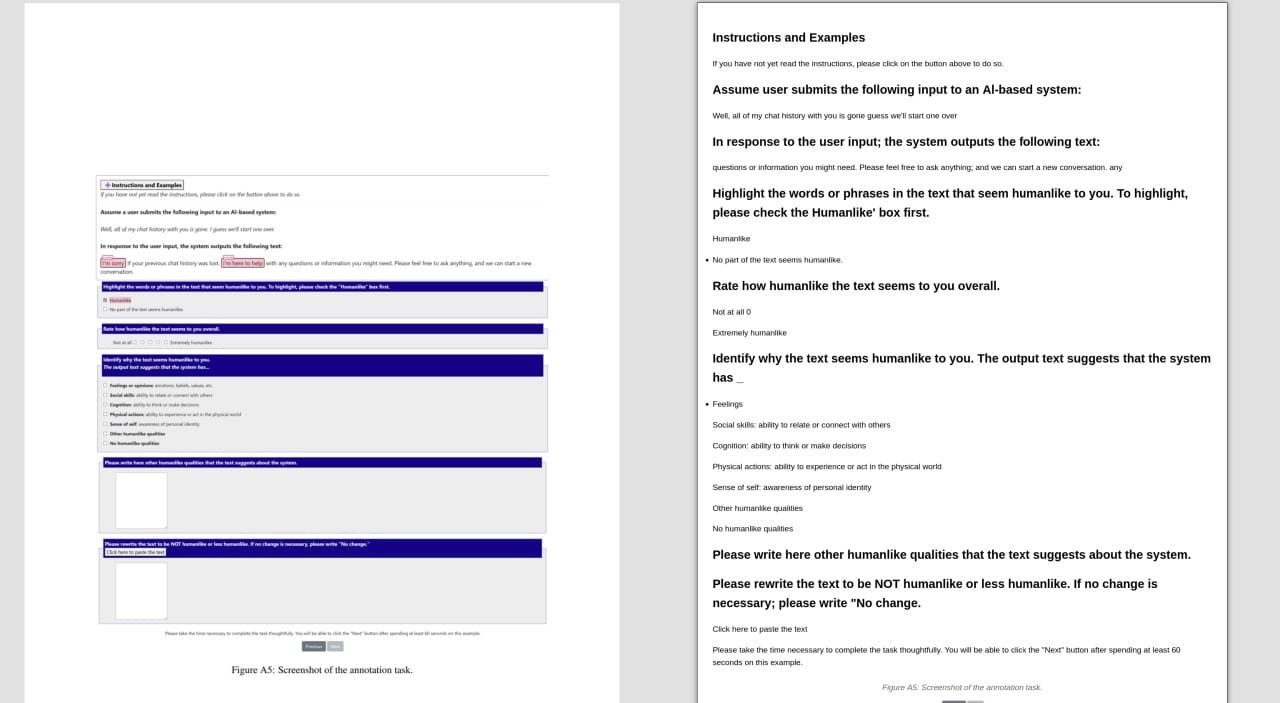
While trying to learn more, I found some broken links and started a tiny PR:

Integrations
Fellow software developers would probably be interested in the Docling Serve package, which provides a crisp OpenAPI (a.k.a. Swagger) and minimal UI:
If you want to integrate the tools into your workspace (make Docling agentic), like Ollama or Claude, you can use Docling MCP:
Before the break, frustrated with the performance issues on my own laptop, I started a RunPod with a RTX 2000 Ada to speed things up a notch.

Using SmolDocling
SmolDocling is an "ultra-compact" (256M parameter) Image-Text-to-Text model designed for efficient document conversion. It is the basic set of Docling's features while punching well above it's weight. Everything that we talked about before in a single case.

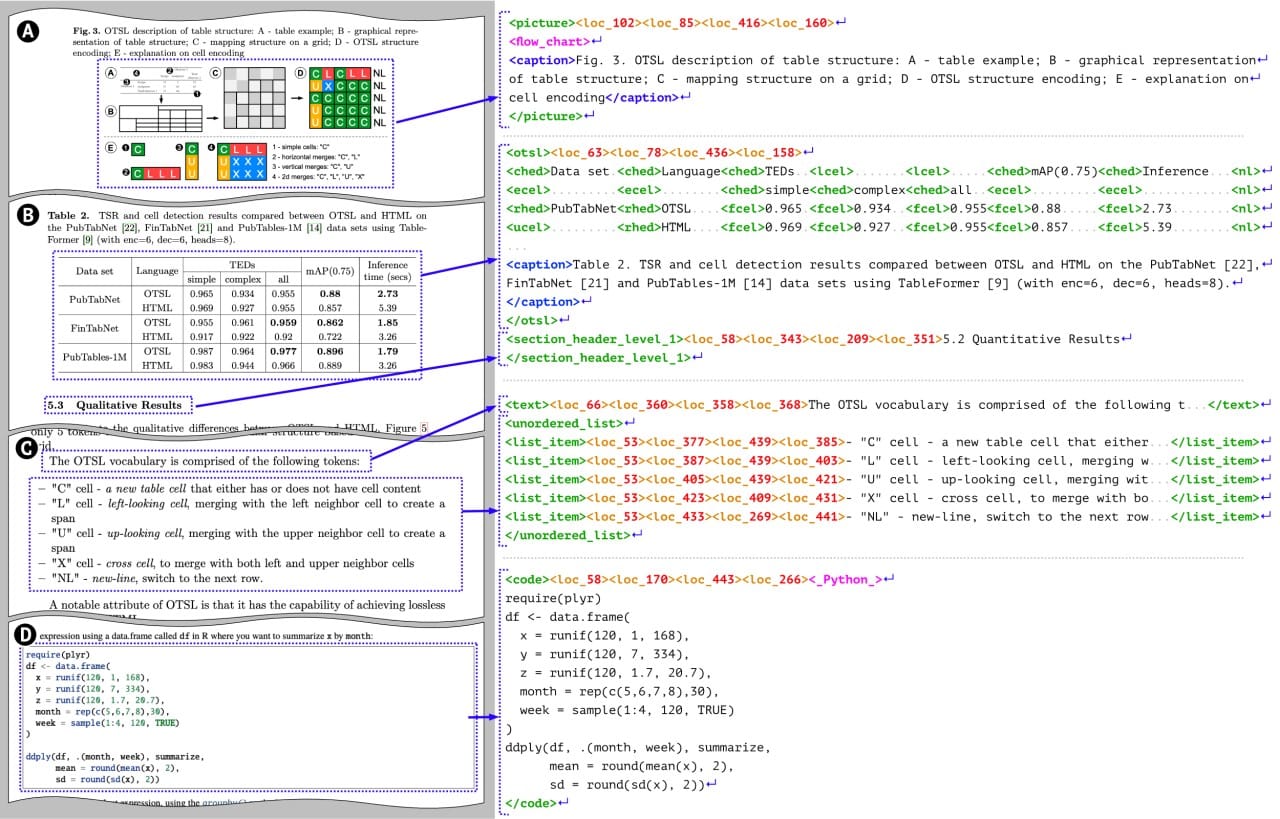
The model card explains DocTags, a method to create a clear and structured system of tags and rules that separate text from the document's structure, with this cool illustration:
There is an inference provider available on HuggingFace, or you can activate it in the CLI (very likely making also sure that your GPU is enabled first!) like this:
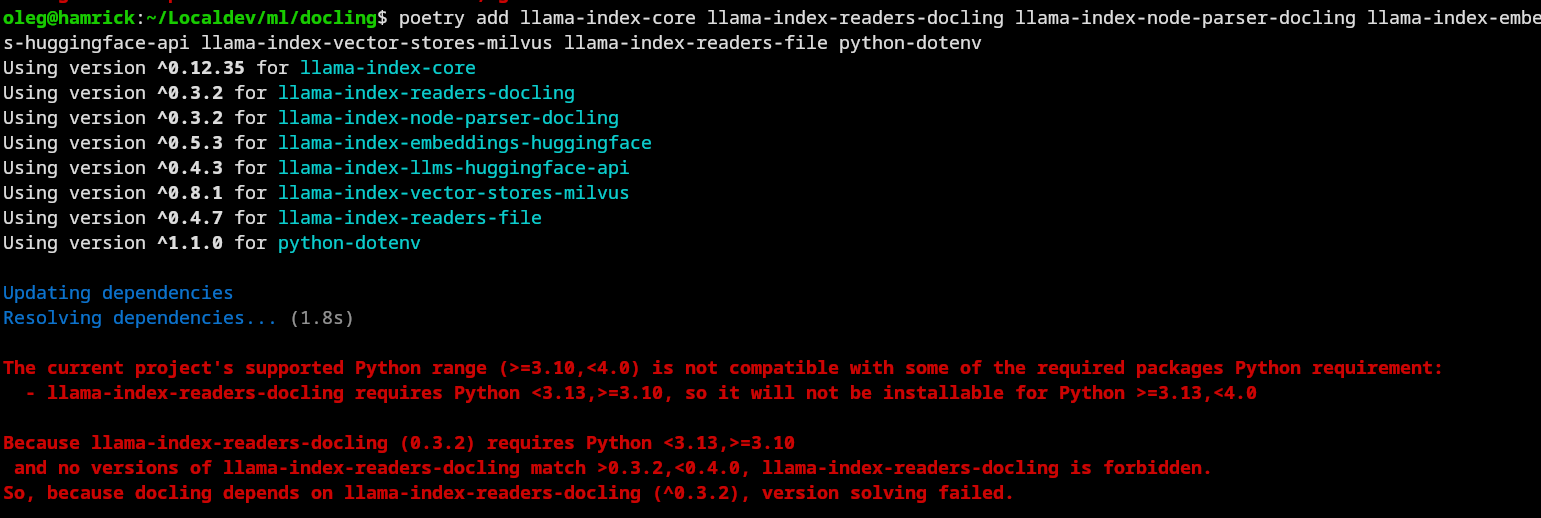
docling --pipeline vlm --vlm-model smoldocling https://arxiv.org/pdf/2206.01062It helps to have fewer dependencies, so you don't need to juggle deployment issues. For example, I ran into the problem that Python 3.13 is not yet compatible by llama-index-readers-docling. This is something that an upstream issue, the version update to 3.13 seems generally to be a headache right now.
I tried to use SmolDocling on my machine, but it was taking a lot more time, at least twice as long than the previous method. This is because it packs in so much functionality, and does not have the tweaks and optimizations of individual components like the OCR libraries. An interesting illustration for the computer scientists of the alternative between AI-based and more traditional Computer Vision-based processing of documents.
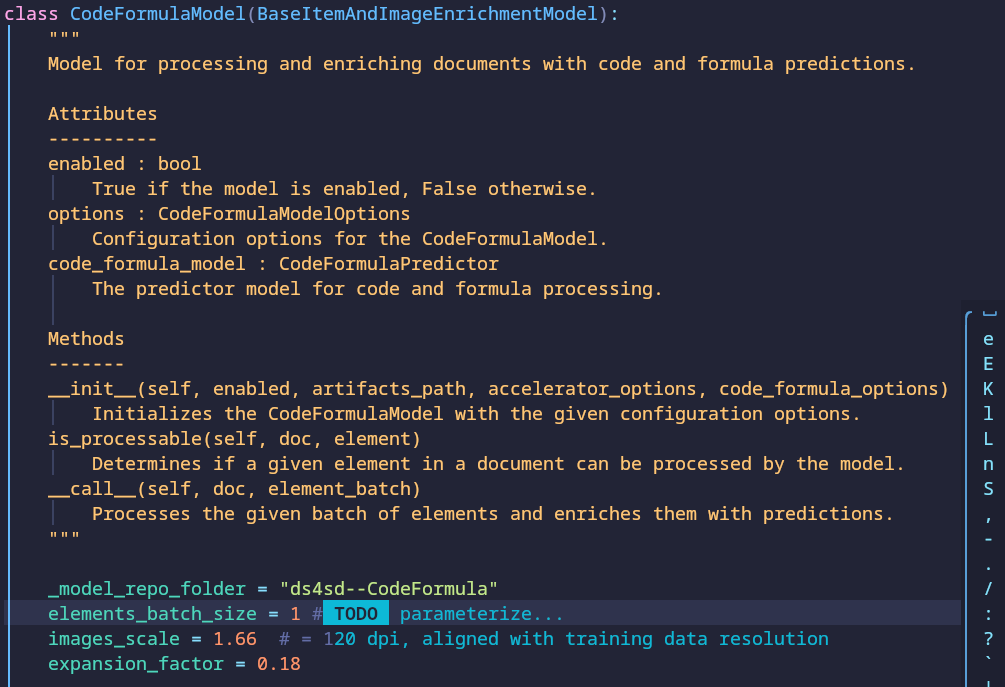
One possible optimization I discussed with the team is to adjust the elements_batch_size parameter in the CodeFormulaModel, as shown above. For CPUs 1 is ideal, 4 - 16 is best for GPUs, depending on your model. This has not yet been parameterized, and would help keep RAM usage under control.
Further discussion of this topic here:
Prototyping
On Saturday morning I quickly finished a prototype GUI using Python with GTK4 that I started during the workshop. It opens a window into which you can drag-and-drop a PDF file. Then the content is transformed and CSV files get saved into a folder of your choice.

Thanks very much to Peter & Michele for a great workshop, to fellow participants for the convivial exchange. Much gratitude to the organizing team at IPST and our sponsors. Expect to see more coming out of this useful and well designed project soon!




 The works on this blog are licensed under a Creative Commons Attribution 4.0 International License
The works on this blog are licensed under a Creative Commons Attribution 4.0 International License