110 #apertus #instruere

Continues from my previous post, where some history of the development of open source AI projects was followed by discussion of the new Apertus frontier model from Switzerland. Here is a summary of this article by Apertus 8B: (*all spelling in context!)
The article covers the aperture model (built by the Swiss AI Initiative with an open-source ethos), its capabilities, setup options (cloud or local with hardware considerations), and the importance of community input for trust and governance.
It also touches on broader questions about open data, model transparency, and the Swiss cultural/national context of the model's launch. (see Thoughts on Open & Closed)
Practical tips for developers or researchers on downloading, using, and setting up the model are provided along with resources (e.g., in the cloud, Ollama, Hugging Face, and vLLM) and explanation of costs.

From the slides of the Apertus Tech Sessions prepared for the Swiss {ai} Weeks, we are clearly reminded that the goal of the project is to 1) "Develop capabilities, know-how, and talent to build trustworthy, aligned, and transparent AI." and 2) "Make these resources available for the benefit of Swiss society and global actors" - i.e. nowhere does it say that we should expect a production-ready service. The sessions note that our goal here is to help create an open development ecosystem – especially as open models approach closed model in performance over time.
We have seen charts like these, and want to join into the fray:
What we know is that the Apertus model was trained on the Alps supercomputer, operational at CSCS since September 2024, a data center of over 10'000 top-of-the-line NVIDIA Grace-Hopper chips, with a computing power of 270-435 PFLOPS, reportedly in 6th place (June 2024) globally.
Here is how Apertus compares 'on paper' with similar models:
| Model | Parameters | Openness | Language Coverage | Training Hardware | Strengths |
|---|---|---|---|---|---|
| Apertus | 8B / 70B | Open Source, Weights, Data | >1,500 | Alps: 10,752 GH200 GPUs | Linguistic diversity, data privacy, transparency |
| GPT-4.5 | ~2T (estimated) | Proprietary | ~80 - 120 | Azure: ~25,000 A100 GPUs | Creativity, natural conversation, agentic planning |
| Claude 4 | Not published | Proprietary | ? | Anthropic: Internal clusters | Adaptive reasoning, coding |
| Llama 4 | 109B / 400B | Open Weight | 12, with 200+ in training | Meta: ~20,000 H100 GPUs | Multimodality, large community, agentic tasks |
| Grok 4 | ~1.8T MoE | Proprietary | ? | Colossus: 200,000 H100 GPUs | Reasoning, real-time data, humor... |
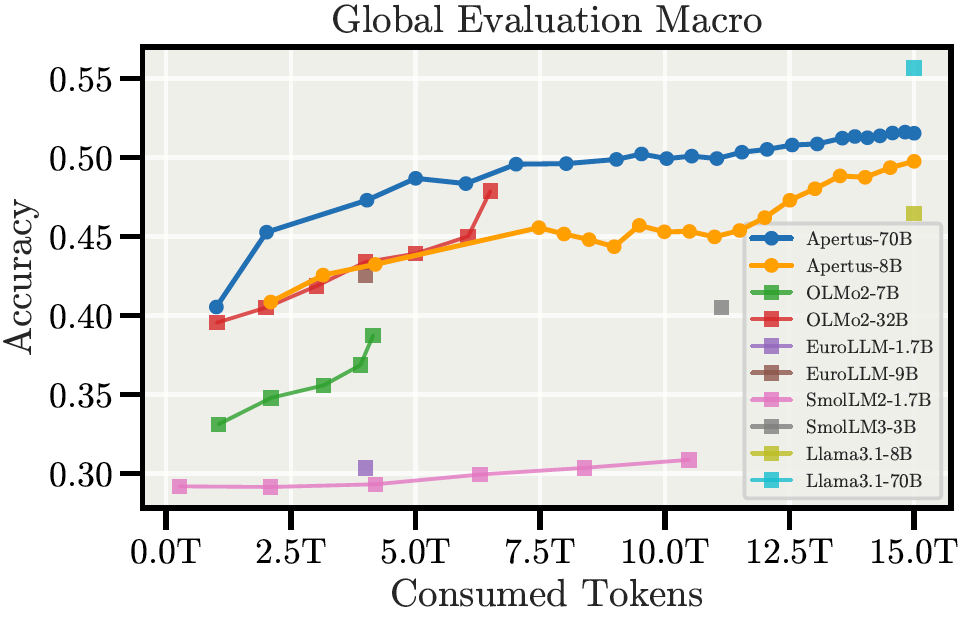
With a basis of approximately 15 trillion tokens, a LOT of data has gone into the preparation. Particularly noteworthy is the high proportion of non-English data (40%) and coverage of over 1,500 languages, including rare ones like Romansh or Zulu. The data was ethically sourced - without illegal scraping, respecting robots.txt and copyright requirements. While this limits access to certain specialized information, CSCS emphasizes: «For general tasks, this doesn't lead to measurable performance losses.»
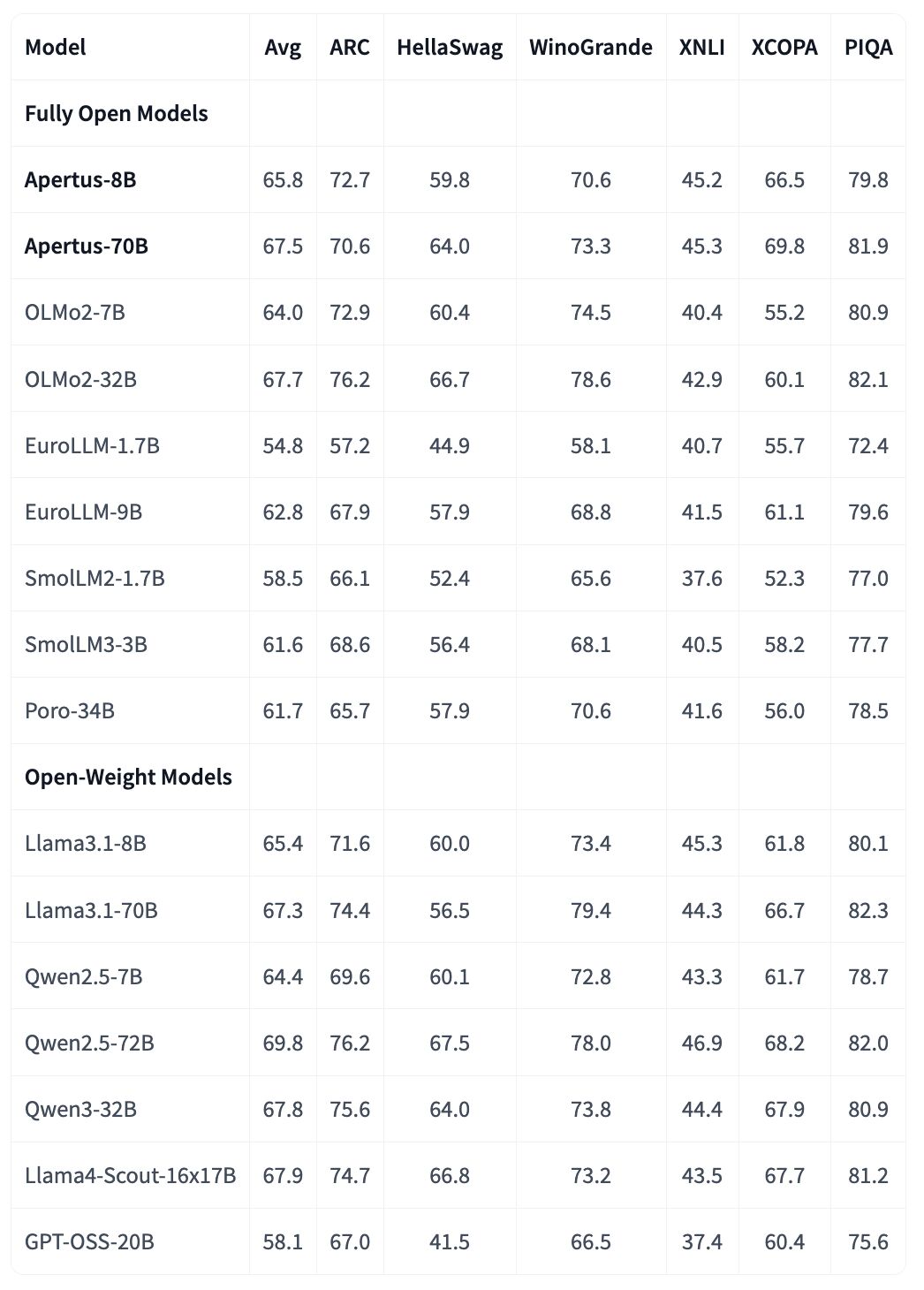
The Evaluation section of the Apertus Model Card, Section 5 of the Tech Report have various data on evaluations, and I recommend the blog posts at effektiv.ch for a good overview. In the following sections, I will focus on getting the model up and running for your own testing.
Apertus in the cloud
There are already several good options for playing with Apertus with a minimum of set up, as I have outlined in the Resource section of our Bern {ai} Hackathon last week:

Direct link: https://chat.publicai.co/
Direct link: https://digital.swisscom.com/products/swiss-ai-platform

Direct link: https://www.begasoft.ch/brandbot
Direct link: https://huggingface.co/Swiss-AI-Weeks
With kind thanks to the three providers above, we managed to have a good start last week. Our hackathon platform swissai.dribdat.cc (Dribdat) is connected to the PublicAI API, whom we thank for the free service – generating evaluations for all the teams, like this:
We also added a RunLLM widget (kind thanks for sponsoring a free agent) for user support, and potentially comparison with Apertus:
Would you like to run your own LLM, on premise or in the cloud? Then we need to have a quick talk about the money.
If I were GPU-rich ...
A famous musical scene from the movie Fiddler on the Roof (1971)
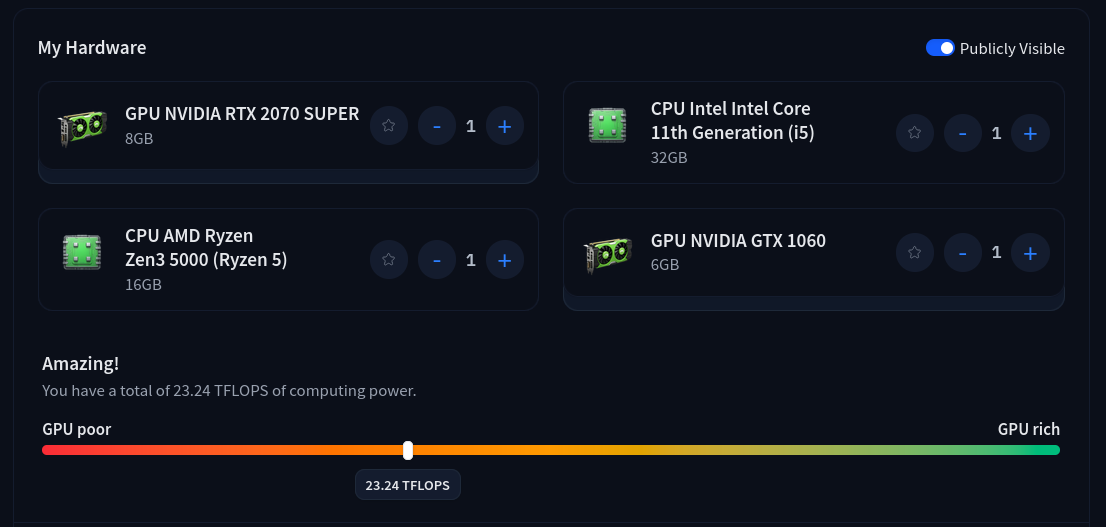
On my Hugging Face profile, you can see the hardware that I brought to our Bern {ai} Hackathon last week: two rather average workstations, at current market prices around 700 CHF each. They are representative of what most enthusiasts could afford. 23.24 TFLOPS is actually not that bad, as far as value for money goes.
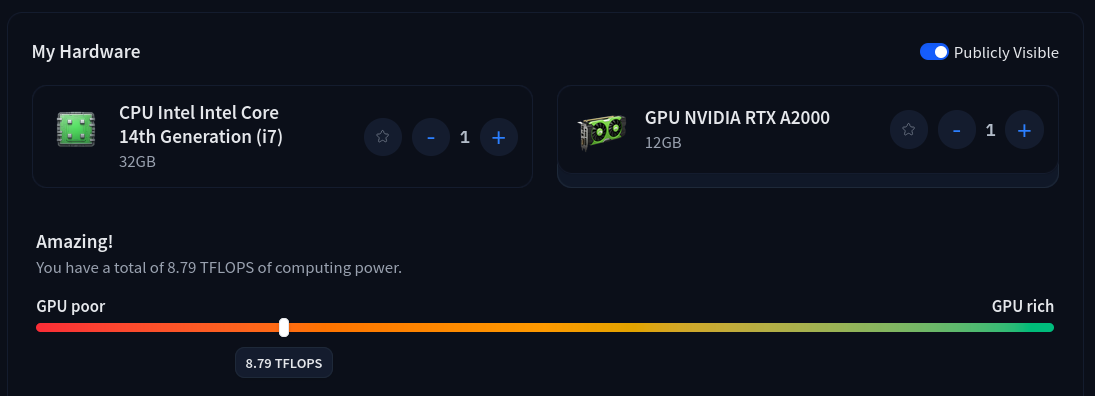
The workstation we borrowed for the Data Hackdays in Uri (shown above) was significantly more powerful - costing a factor of 2 - 3X more than the builds above. Nevertheless, it comes at less than half the TFLOPS - reminding us that these values are only a rough approximation of true performance. Read see the project report of our local AI installation in Uri here (in German).
In my tests, as you will need to reserve some memory for your operating system and programs, at least 16GB of VRAM and ideally 20GB should be available to run the smaller Apertus 8B model, as it was provided on launch day. In other words, you would need to try to get a hold of a top-of-the-line graphics card.

This could be the NVIDIA RTX 4000 SFF Ada pictured above, currently retailing at around 1150 CHF, or the RADEON RX 7900 XTX which is about 800 CHF – though note that support for Radeon chips can be a bit patchy. Oh, and even then, don't expect to get much performance out of it: you probably want to get 2 or 3 of such cards in an SLI setup 🤑
Comparing Apples to oranges?
Given the situation above, it is understandable people feel that the most cost-effective way to get the Swiss LLM in house today is Apple hardware. The current Mac Mini with an M4 chip and 24 GB unified memory should be enough to run Apertus, and retails for < 900 CHF at the moment. Going up up up to 12'000 CHF for the behemoth 512 GB version.
Clearly we are not comparing apples to apples here: the way that NVIDIA, AMD and Apple measure their GPU cores and ALU units differs. Your performance may be quite different depending on the way your platform is set up, and models themselves need to be optimized to run decently on Mac hardware in the first place.
And you have to ask yourself: just how hot do these things get? The performance of a powerful Mac Studio (192GB Unified Memory) was evaluated at our hackathon in the Measure footprint of open LLMs project. Here are two charts excerpted from their report:
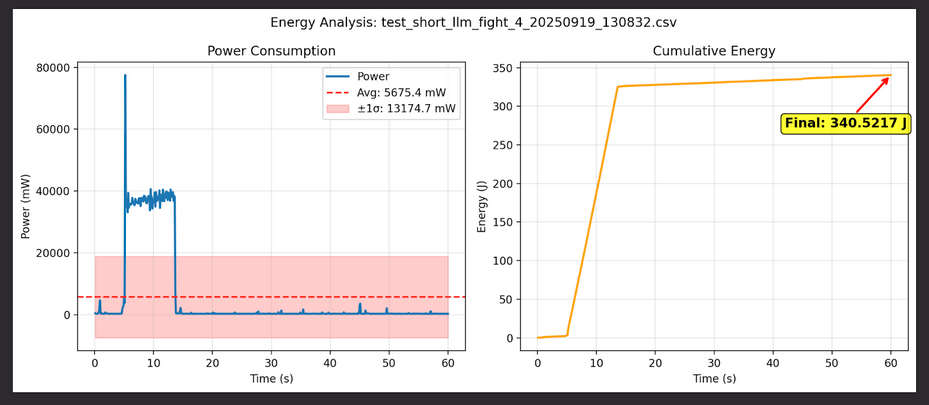
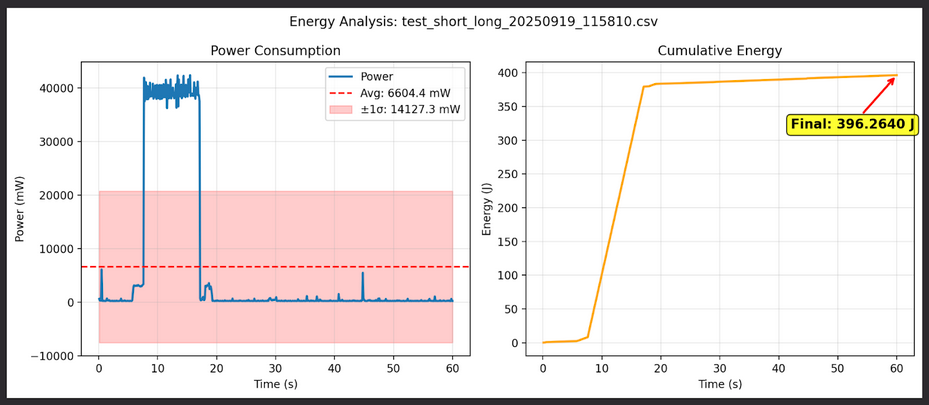
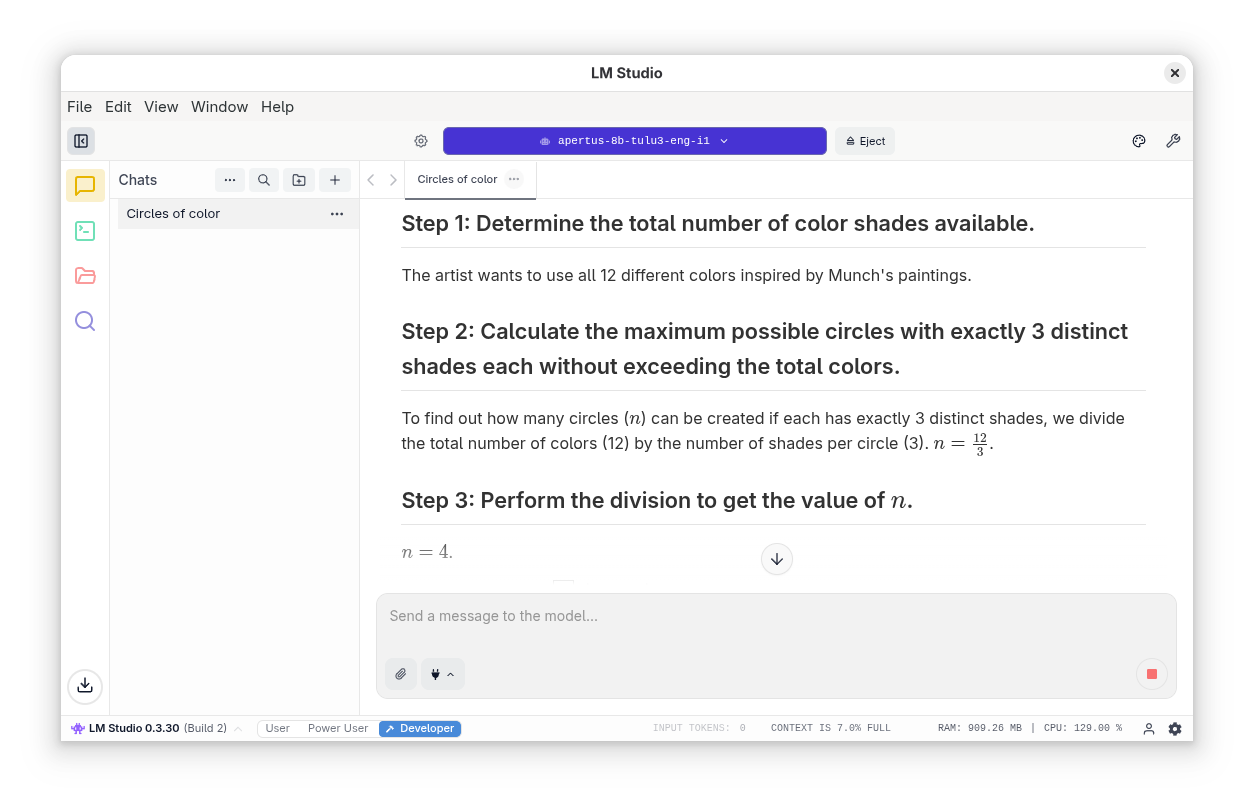
There are plenty of installation guides online for Llama, that you can also use to install Apertus on your Mac. I have particularly heard good things about the combination of LM Studio with the MLX quantizations. Cool.
There is a lot of debate out there about what constitutes AI-level hardware, and certainly the push to sell new computers is one of the major factors in the global race to build capacity. Just for fun, here is how my Hugging Face profile would look like if I had 4000 Grace-Hopper units, which were used to train the Apertus model 🤗

Whether you are GPU-poor, or GPU-rich, what software do you need to work with Apertus? I will discuss Ollama and vLLM in the following section. Others have reported good performance with LM Studio (Macs) or Lemonade (Ryzen). Another client I have been recommended is Jan.

Using Ollama
Models downloaded from the Ollama library can be configured and managed most easily with an elegant chat interface of Open WebUI. This is my default option, as I have run a shared server in the office and at home for over a year with open weight models like Llama, Olmo and Qwen. The information here also applies to other software based on the llama.cpp library, such as the popular LM Studio.

Due to some bleeding edge methods used to engineer and parametrize the model, we had to wait for a new release of the library and software.
[Updated] As of October 20, the 0.12.6 release of Ollama includes a new release of the library with the needed support. You won't find Apertus in the Ollama library yet, and indeed the standard model does not yet run, as GGUF (a popular binary format for models) support is lacking. However, there are several community remixes of Apertus available that have you covered, such as 8B releases by bartowski, redponike & unsloth, all tested by me with (on first glance) sensible outputs.
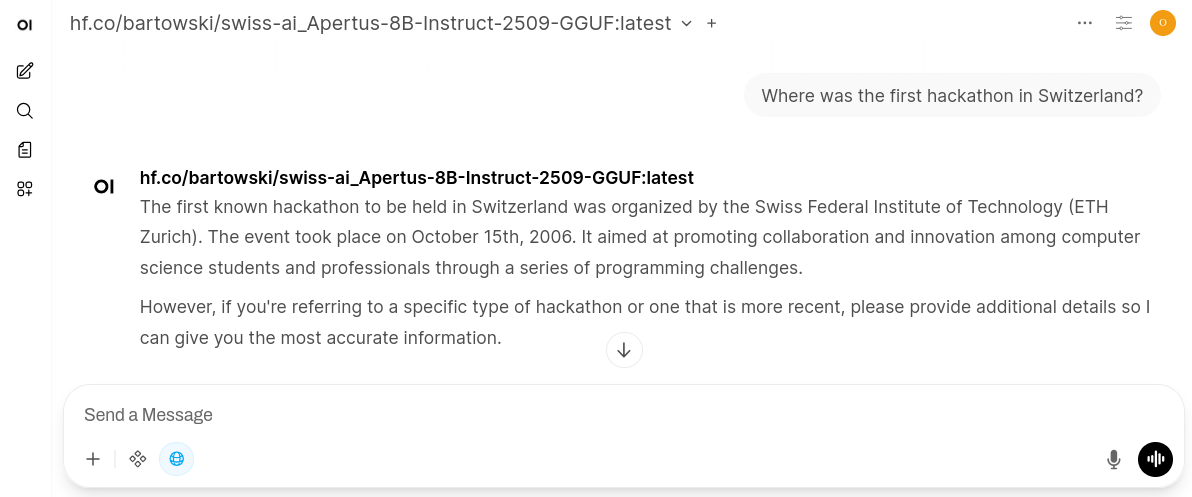
Even with an 8GB consumer-grade video card, it is already possible to run Apertus at home. To get started, just run a command like this in your console where you have Ollama installed:
ollama pull hf.co/bartowski/swiss-ai_Apertus-8B-Instruct-2509-GGUF:Q4_K_M
Some people have reported strong hallucinations and high CPU usage, so your mileage may wary. The upcoming version of llama.cpp should improve performance.
Feel free to share your experiences with the community in the discussion area.
Find more quantized versions of Apertus in GGUF, FP8 or MLX formats on Hugging Face. You may still need to write a Modelfile, include the chat template and other bits for a complete model specification if you get errors like this:
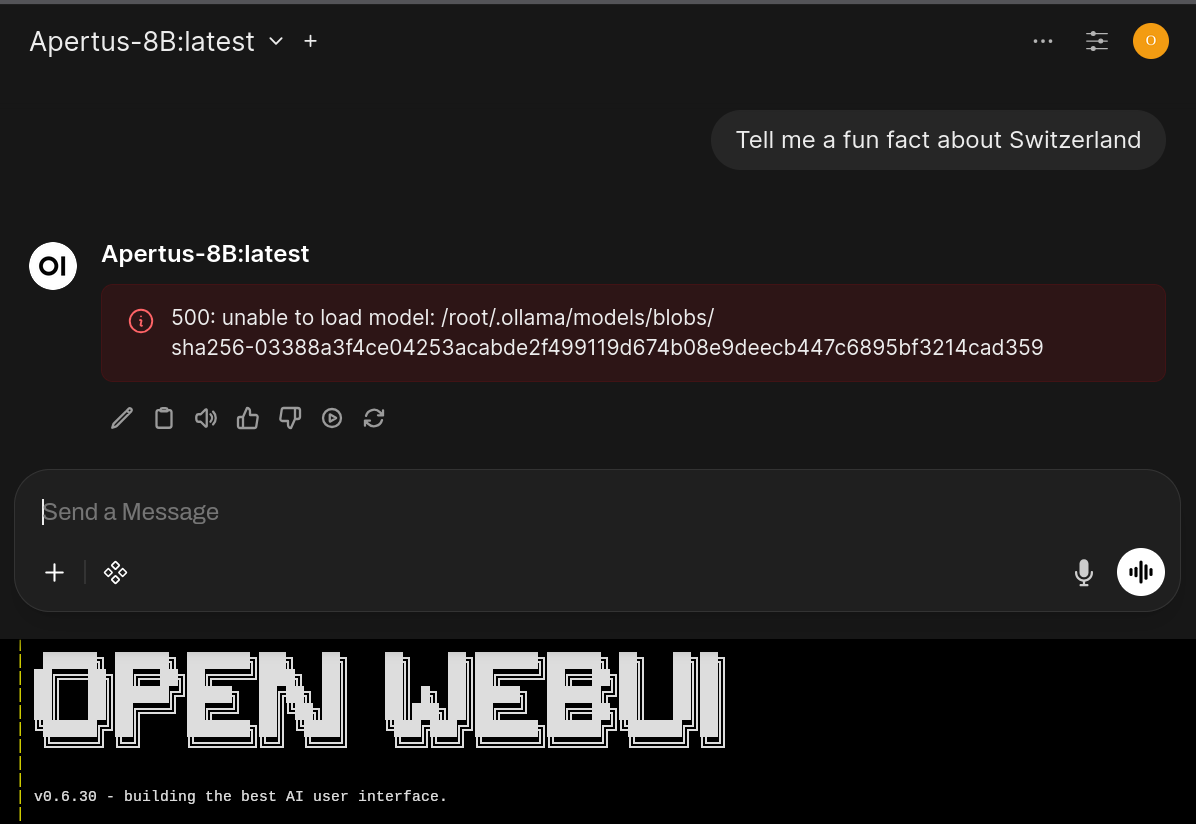
I am involved in the discussion and testing nightly releases: stay tuned!

See also the CH Open & BFH workshop described in my previous blog, with links to a video and slides where the ecosystem around these tools is discussed:

Using vLLM
This is the route recommended by the Apertus team, and was available from day 1. Based on this, PublicAI and other providers have launched their inference services.
vLLM is a fast and easy-to-use library for LLM inference and serving. Originally developed in the Sky Computing Lab at UC Berkeley, vLLM has evolved into a community-driven project with contributions from both academia and industry.
For a software developer, the library may be easy-to-use, but deployment is not simple. Nevertheless, for an IT team the multiplatform deployment and integration with DevOps tools like Kubernetes would make a lot of sense. Once you have the NVIDIA libraries and CUDA tools set up, a relatively simple way to start vLLM is with Docker.
I have prepared a script, tested with a basic 16GB GPU machine on Linode: the RTX4000 Ada Small, which costs $350 CHF per month ($0.52 per hour) in my region (Frankfurt - Germany). If there's interest from the community, I will put the recipe into a StackScript. Note that you need to agree to NVIDIA's licensing conditions to use their proprietary libraries. My scripts can be downloaded on GitHub, or here:
You should also create a .env file or pass in a couple of environment variables otherwise:
- Set
HF_TOKENto a token you generated on your Hugging Face settings, making sure to allow "Read access to contents of all public gated repos you can access". - The
HF_MODELparameter should be set toswiss-ai/Apertus-8B-Instruct-2509- or to any other model, or remix of Apertus.
Note that I'm using the 'nightly' version to make sure the latest Transformers library is used. I've also set max-model-len to a low 4K (the default is 64K, you probably want to use at least 8K), which you can increase if your system allows it.
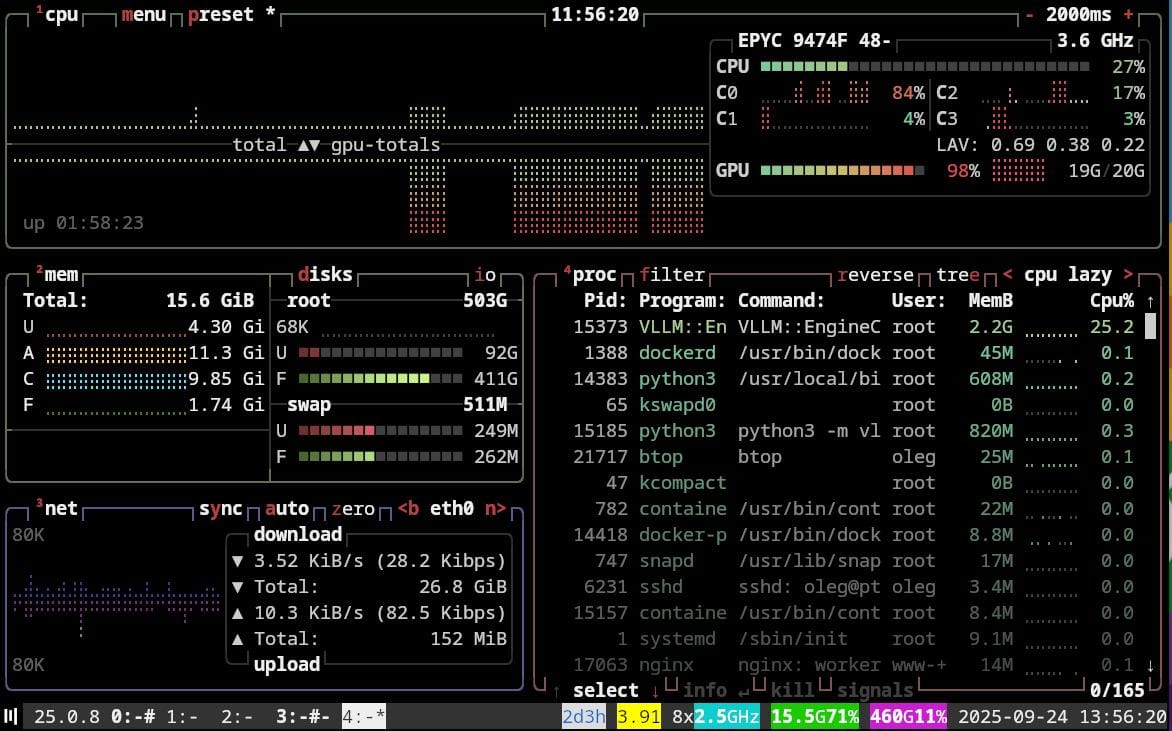
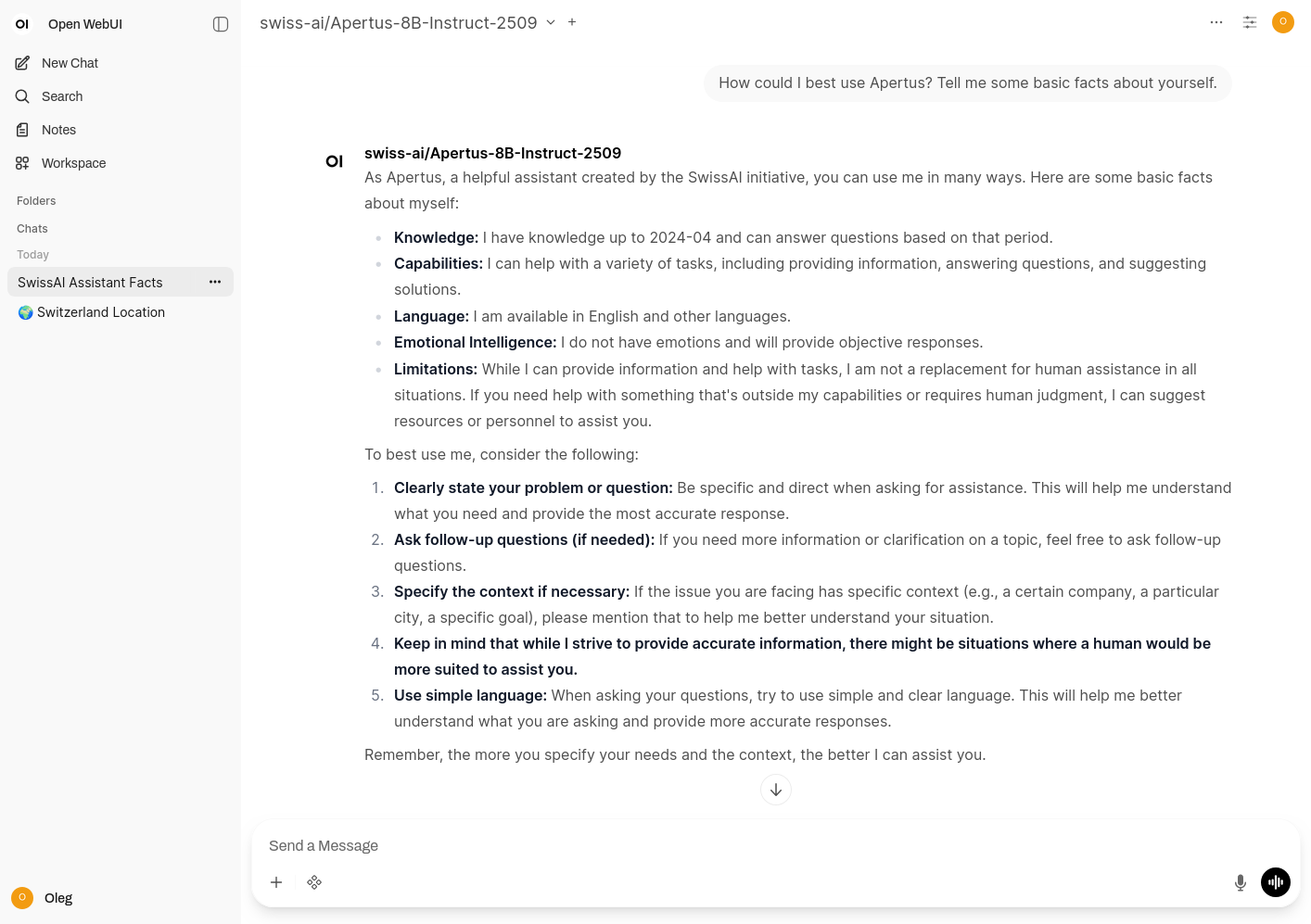
Using Hugging Face
Most of my initial experiments are in a Hugging Face Space, mirrored in a Codeberg repository, which can be used by developers during our hackathons. It has a typical completions API with the recommended System Prompt, as well as some optimizations and other ways to query the model using the Transformers library.
In addition to the space, I've prepared an Apertus 8B Instruct 2509 endpoint which you can use with a Hugging Face token. Thanks to support from the HF team, this can be easily deployed on your own by entering the model's name at endpoints.huggingface.co:
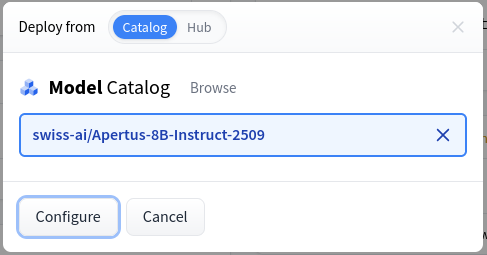
Make sure to configure the auto-sleep options to your liking. Too short, and you'll be frustrated by the long startup times. Too long, and you may be surprised by a large credit card bill (though you can also set spending limits in the Billing section).
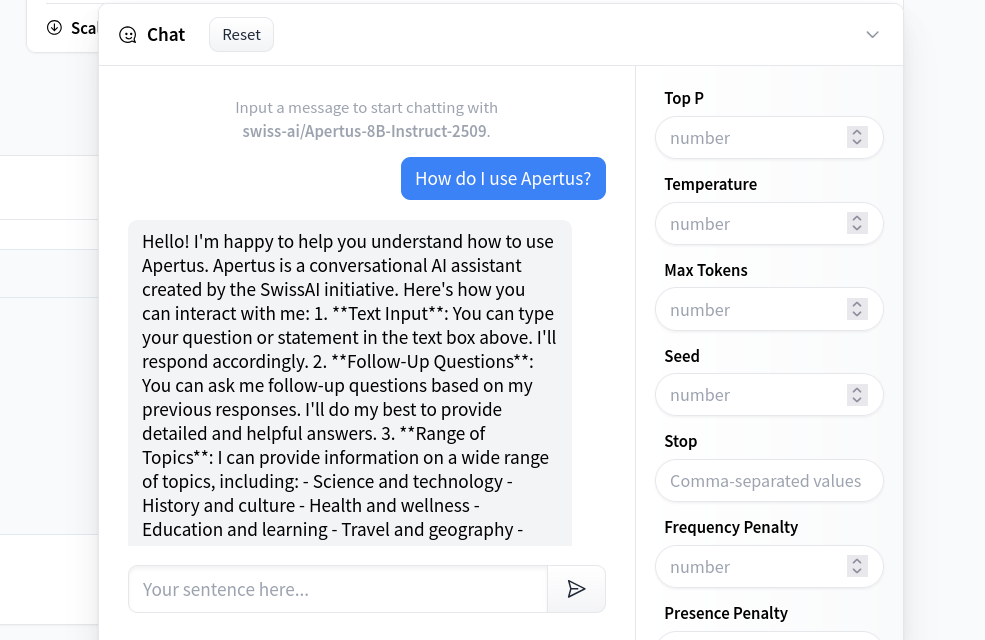
Many thanks and kudos to Leandro and team for their tech support, and giving out free credits, stickers, badges and other goodies to participants of our hackathon. I really encourage everyone to check out their learning resources online:

What's in a name?
If I may diverge from strictly technical topics for a moment. Using a Latin word in the name is a quaint choice, but not extremely original. There are several companies with it in their trademarks, so some legal discussion will surely be necessary. The relatively inactive apertus.org project is an open hardware camera. This is alluded to by the generative image pasted at the top of this blog you're reading. There is also the Apertium free/open source machine translation platform, but we don't need to talk about that now.. <ahem />
"Professor Nümmerli" made a quite humorous take on the subject (a fondness for Swiss German humor is recommended) in a video posted by comedian Mike Casa on Saturday.

It's a good name. One can get used to it.
Thoughts on Open and Closed
Upgrading from existing tools and systems to new ones, especially when it involves innovative AI models like Apertus, often requires a careful reconsideration of old and new. I get the feelings of responsibility, a sense of stewardship over projects embodying the values of openness and community empowerment.
The choice of the Apache 2.0 license suggests transparency and intention to foster open & global collaboration. However, we also need active, public discussion around the choice of licenses and governance models. The rhetoric around openness can sometimes mask real concerns, so understanding the logic behind this choice and whether it aligns with community principles is key.
The decision to publish Apertus initially on the Hugging Face site, for which there is currently no direct equivalent in Switzerland, plus the absence of any mentions on SUPSI, CERN, or other universities, has been somewhat conspicuous. It seems to me that the gated (registration required - the "You have been granted access" in my screenshot at the top) initial publication of the Apertus model has provoked the most skepticism.

I chatted about this with Apertus, and got some sensible action items to foster trust:
1) Involve the Community in Key Decisions: Engage with open data advocates early and often. Open forums or public consultations on model development, governance, and licensing can address concerns proactively.
2) Transparency in Data and Governance: Publish more documentation on data sources and training processes. Include explanations of the decision-making process around the choice of license and motivation for the current deployment strategy.
3) Strategic Partnerships and Affiliations: Explore and communicate about whether there are less visible partnerships or affiliation that would explain the current institutional landscape.
4) Open Data Interoperability: Consider discussing integrations or complementary strategies with Opendata.swiss, Zenodo, and similar open data platforms to enhance accessibility and visibility but also value governed, controlled access.
5) Highlight Accessibility and Fairness: Ensure that while the main model is accessible through a controlled portal, there exists a pathway for researchers and developers to understand, audit, or build upon the model with clear guidelines and support for responsible use.
Speaking of involving the community: have you signed up to a Swiss {ai} Weeks hackathon yet? (This clip is also on Vimeo)

Connecting to Apertus
It's reasonable to take a step back to ensure that the model is indeed what it promises to be. Legitimate questions about the dataset's origins, compliance with legal and ethical standards should be addressed. Understanding the model's capabilities, the intentions and process behind its creation is fundamental, not only to trust but also to meaningfully engage with and potentially contribute to its roadmap. Here are some places where this is happening:
GitHub repo from the Swiss AI team

Hugging Face community

Our hackathon wiki
Further helpful references






 The works on this blog are licensed under a Creative Commons Attribution 4.0 International License
The works on this blog are licensed under a Creative Commons Attribution 4.0 International License