On Monday, a close knit group of international experts from around the world met in Lausanne to advance open and collaborative AI development, the proceedings of which I had the privilege to support and contribute to in a workshop setting. The Open-Source LLM Builders Summit was hosted by the EPFL AI Center and ETH AI Center on behalf of the Swiss AI Initiative. My notes in this blog are of a personal nature, and should not be taken as an official statement.
Open source LLMs are released under open-source licenses, allowing anyone to use, modify, and distribute them freely. Trained on large datasets, they can perform tasks such as text generation, translation or question answering. These models offer powerful tools while promoting inclusivity and transparency, but their use requires careful consideration of technical, ethical, and legal factors. Early examples include GPT-J (Apache license), BLOOM (RAIL), XLM-R and GPT-2 (MIT).
While the focus of the talks was mostly on the technical development of LLMs, among the participants were people collaborating on Public AI: an actively researched concept and platform to provide access through a public inference utility. I spoke about this recently in an aiLights webinar – not needing to host the models themselves makes open source LLMs more accessible and usable by the general public, especially for those who may not have the resources or expertise to deploy such infrastructure. We covered this in the later workshop sessions.
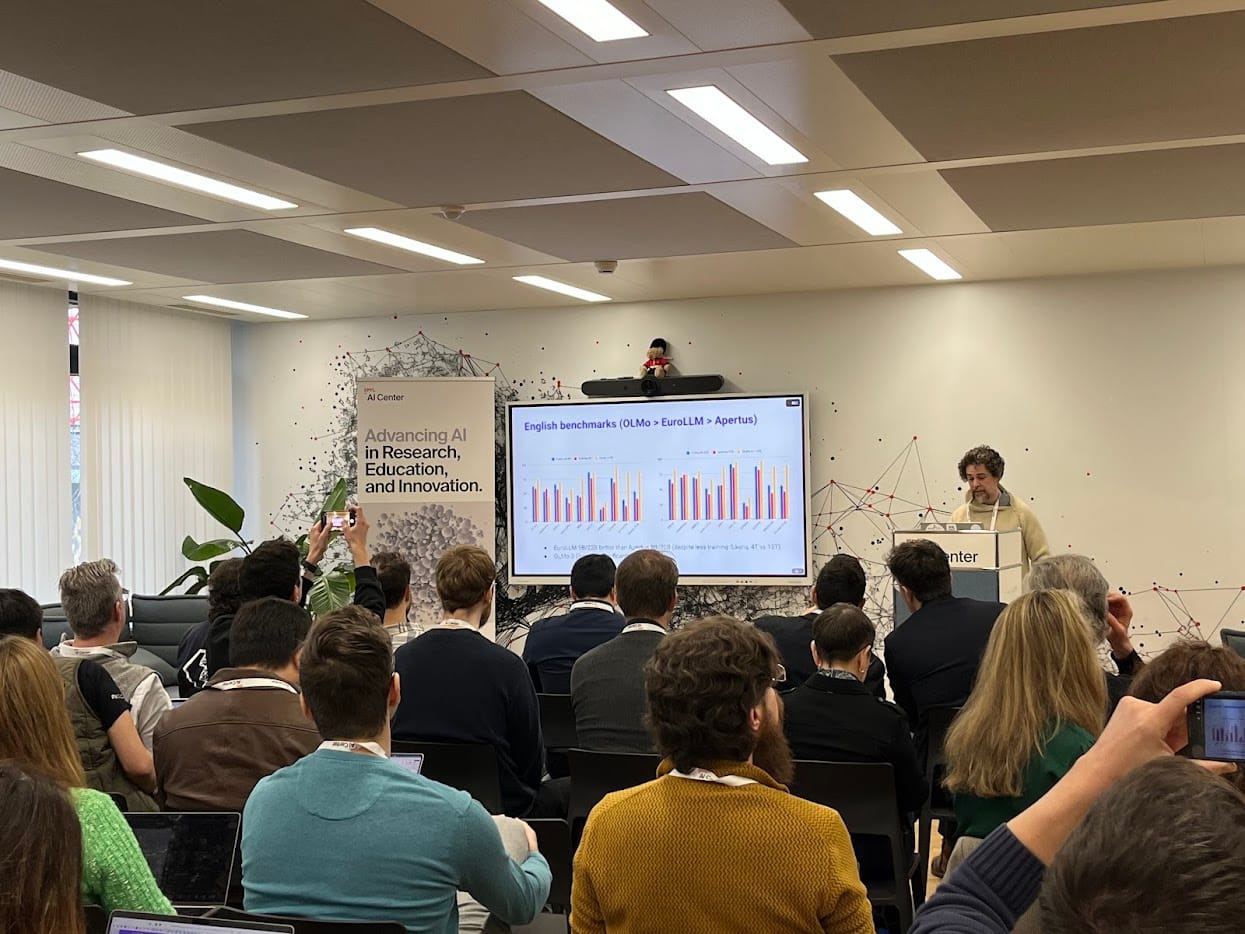
This was the second edition of the LLM Builders Summit (see 2025 PR, recap, slides, videos), emphasizing the importance of collaboration, open standards, and growth of international projects. The presentations ranged from a historical view on CERN’s collaborativeprinciples, to pervasive arguments on the need for transparent governance in open models. The day highlighted the work of diverse teams using centralized training infrastructure (e.g., Apertus, EuroLLM, SEA-LION), covering their progress and challenges.
Photo (c) EPFL AI Center, used with permission
We discussed the value of standardized reporting, community building, and public infrastructure access in breakout sessions. Practical challenges of data sovereignty in a legal sense, and sustaining long-term commitment in the financial, were covered alongside the strategic importance of developer engagement. The event underscored growing international efforts toward transparent, collaborative, and open AI development for the public good.
Model teams
In my notes below, you'll find links to the publications and community hubs of the various LLMs that were represented today. Update 6.3.2026: a couple of glitches have been addressed, after this table was used in a presentation – with my apologies & gratitude for the feedback.
We started the day with a warm welcome from Prof. Antoine Bosselut, one of the Apertus leads and head of the famous NLP lab at EPFL. The group was encouraged to keep minds open to each other, even if we may have quite contradictory ideas on method and milestone.
The day's organizers Federico Fanalistaand co-lead Arnout Devos, representing the two AI Centers, chimed in with the ground rules before we quickly dived in. For the next four hours, save for a short break, we were glued to our seats with an extremely in-depth and challenging set of presentations.
Andreas Hoecker (CERN) helped to further set the tone of the day with "Lessons from International Collaboration", showing how trust, respect, and clear processes are key for complex, visionary projects. He pointed out that long-term collaborations are built on commitment to transparent governance, not just a shared set of goals.
« Successful large collaborations are built on mutual trust, respect, and transparent, fair procedures, with leadership grounded in excellence and expertise. Open and Inclusive governance - through clear structures, representative decision bodies, merit-based evaluation of ideas, consensus building, and collective ownership of major decisions - ensures that all members, including early-career researchers, have a voice and that innovation is encouraged and rewarded »
Dr. Imanol Schlag was up next to give everyone a quick deep dive on Apertus, starting with the broad perspective of unprecedented investments globally and in Switzerland, focusing on the technical and infrastructure challenges in training the first, and a roadmap for the next model release 1.5.
With swift delivery, he put the world of Fully Open LLMs on one page, and outlined ways we already cooperate through the various components used in training and supporting open source models.
Dr. Schlag spoke in detail about the "fully open" path with Apertus, balancing legal and technical challenges to keep data and models transparent. The tough road ahead is one we need to stay on, with sights aimed squarely on the public good.
The EuroLLM team via André F. T. Martins next showcased their work on transparent, standardized training , and highlighted the importance of reproducibility in AI research. It is important to have a shared language for all the labs, an important task at the European level.
This was the first model that I ran in a production setting with the Farming Hackdays last year, and the group has come a long way. Their adherence to European principles is illustrated in their exciting 22B model release a few days ago. Let's get benchmarking!
Kyle Lo (Allen AI) gave as quick and super practical talk, showing us new tools for data mixing that can boost model performance — the critical issue of not just throwing in more data but making sure it is the right mix. That was super practical, and got some of us scribbling notes for our own projects.
Colleague Luca Soldaini joined to talk about State of the Art Reasoning in-depth.
Hector Liu (Kimi AI, MBZUAI) next described the "uphill battles" of open model development—how to sustain it despite funding and talent gaps. It felt like he was telling us to be realistic: share the load and be smarter about resources, and one in particular: talent! The discussion included thoughts on large scale distributed collaboration, open source models, and „high TPP validation using small scale proxies“. Lots of great practical hacks.
Jian Gang Ngui (AI Singapore) shared the SEA-LION model’s journey, which built on a public leaderboard—a friendly competition that drives everyone forward. The talk made me think about how we can do similar for open models, especially with more diverse languages and data.
Matthias Bethge (Tübingen University) presented OpenEuroLLM: A series of foundation models for transparent AI in Europe. We were walked through their work on standardized reporting and the proposed OpenPipeline, which could solve a lot of our headaches when trying to compare models: having a common language for how we report our results.
Yuxuan Zhang (Zhipu AI) next took us through their GLM series, emphasizing the modularity of the architecture and tips on developing multimodal features, which sparked some cool ideas on how we might adapt this for our own open models. This week was a big release (GLM 5), and the energy was tangible.
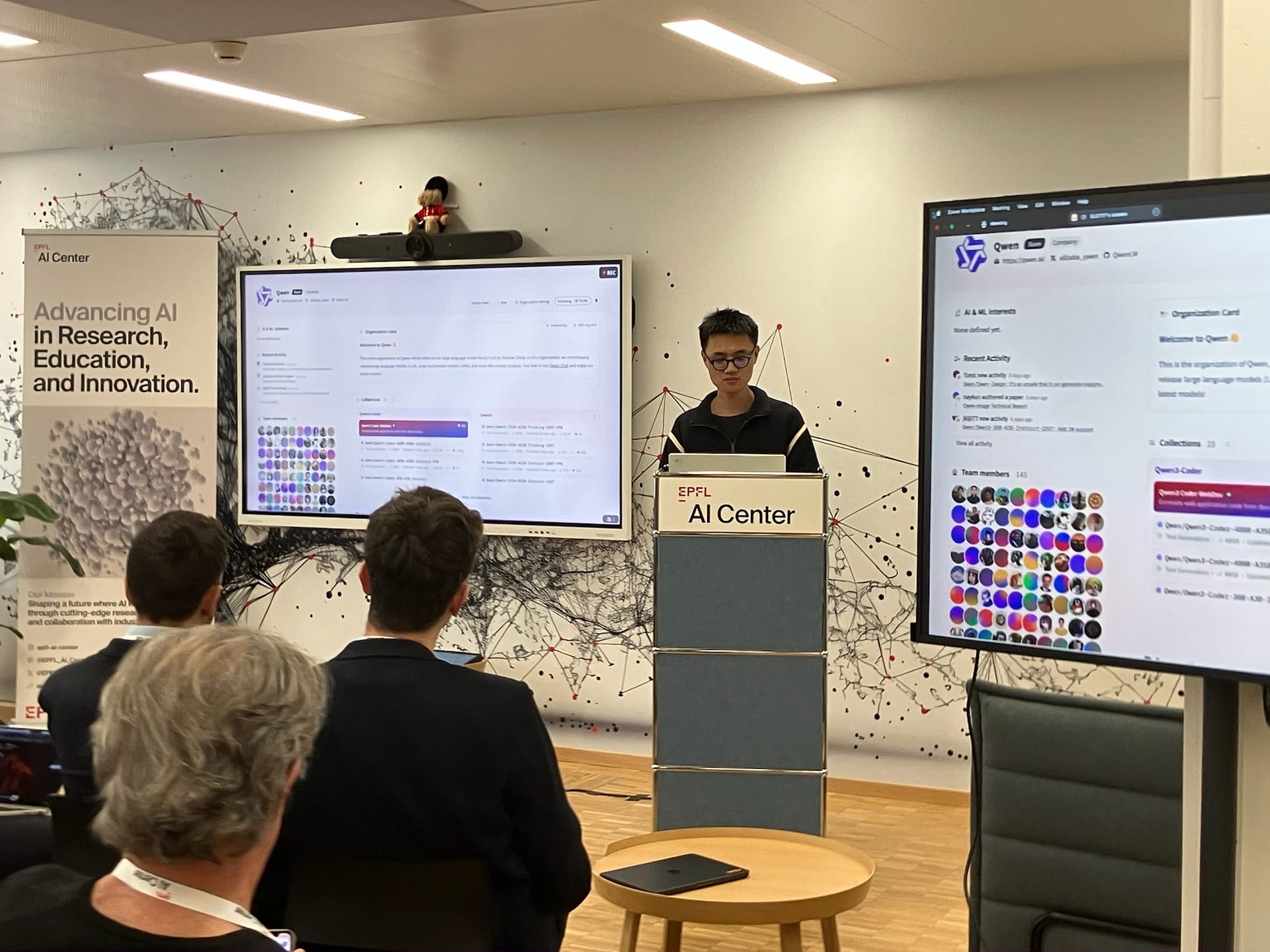
Junyang Lin (AlibabaQwen) brought a fresh perspective on the developer community—how it drives the roadmap of open models. It’s not just about the tech; it’s about the people using it. Keeping a close eye to the needs and opportunities of collaboration, with case studies from the recent Coder Next update.
The models are being trained on a completely different scale here, and it was just fantastic to hear the exchange taking place between the teams. The Qwen team shared that hybrid architectures work, and that’s a good sign for the open models we’re all working on.
Joost VandeVondele discussed production Machine Learning at Scale at the Swiss National Supercomputing Centre (CSCS), in particular the ALPS infrastructure for world-class science where the Apertus model is being developed. He is keeping a close watch of the capacity, making sure the systems are neither over, nor under-utilized. Great perspectives on sustainability aspects, and the open source stack involved. There was discussion of container management, observability, and the ubiquitous problem of early abort.
Timothy Llewellynn (Euresearch) introduced the EuroHPC Joint Undertaking: a set of access calls and collaboration opportunities for the AI Factory model that is being adopted across Europe. The nearly one hundred high-performance computing sites represent a formidable capacity - if it was applied properly. I had a chance to chat with Timothy in the break about the various opportunities the Cross-Cluster program and network for projects in Switzerland.
There were a lot of questions asked and a lively discussion took place in the breaks between the talks. The workshop sessions were where everyone had a chance to contribute in smaller groups. In the one I joined, facilitated by Valentina Pyatkin, we talked about shared infrastructure access – i.e., how to collaborate globally without losing our autonomy.
A workshop participant interacts with a Reachy Mini
Here is a summary of the round table, made with Apertus from my own notes:
We must recognize that collaboration and transparent sharing of data and research are critical for advancing AI, but strict European regulations pose hurdles. The CERN model emphasizes collaboration towards a common goal, but our own AI infrastructure needs to be viable for 40 years, competing with hyperscalers requires strategic partnerships. The growth of Hugging Face and its ecosystem demonstrates the power of organic collaboration, enabling small teams to make significant impacts.
While we've leveraged existing LLM pipelines and large datasets (like Common Crawl and Transformers), competition with American labs is challenging due to current geopolitical tensions. European fragmentation in AI development—with many projects but limited innovation—remains an issue, unlike China’s more unified approach, where open-source contributions are often a prerequisite for cooperation, even within universities.
Photo by Daniel Naeff
Training LLMs locally and contributing to open-source projects, such as through fine-tuning, is recognized and valued. The most difficult aspect remains the training pipeline, especially when faced with diverse hardware (e.g., not just NVIDIA GPUs but also NPUs from Chinese companies) and data scarcity. Datasets are crucial but often proprietary, making it hard to open up without corporate cooperation. We share our training pipeline and code, but pre-training design is more valuable to share.
To address fragmentation, fostering open-source community engagement and collaboration across borders is key. A potential solution could involve aligning with larger entities like corporate acquisitions or integrating with existing smaller platforms, though proving impact through products or academic papers is essential. Ultimately, true success is measured by actual applications and community engagement (e.g., GitHub stars, repo usage), not just model popularity metrics.
A plate of snacks with a roundtable in the background
This year’s summit felt like a professional and empathetic reunion, with the Swiss AI Initiative doing a great job of hosting all the visitors. It was an energizing mix of tech talks, real talk, and tasty food (special thanks to Jocelyne for the Moroccan treats pictured above!) The day ended with a sense of community and engaged perseverance. The summit filled me with a sense that the dark clouds of foreboding over the AI industry carry within them a silver lining of opportunity for these communities, engaged in open development. I am intent to carry the learnings and this conviction into my engagement here today, and in the days to come.
Sunset over the Jura on my way home to Bern
You might also like...
Jan
26
120 #ailights #spiu
A talk on Apertus, Public AI, and a cooperative proposed to connect the two.
6 min read
Jan
13
119 #apertus #mlx
Getting started with local AI: running Apertus with LM Studio on Apple MLX, with thoughts on the Why, What, and How.
14 min read
Jan
12
118 #apertus #nova 🅰️👁️
An experiment in auto-generating a creative response to a blog post. This text was composed by artificial intelligence under the careful watch of @loleg
5 min read
Dec
13
115 #apertus #snai
Notes from the first and second editions of the Swiss AI SME Circle: at the AI+X Summit in October and Altstetten yesterday.
9 min read
Sep
24
110 #apertus #instruere
Learn about my initial experiences working with the Apertus Large Language Model during the Swiss {ai} Weeks, with advice on getting started yourself.





























 The works on this blog are licensed under a Creative Commons Attribution 4.0 International License
The works on this blog are licensed under a Creative Commons Attribution 4.0 International License