123 #winterkongress

Some impressions and my slides from this year's winter congress of the Swiss Digital Society, at the Rote Fabrik in Zurich. The event was held mostly in German. You can find the full schedule, including my talk on Saturday, on this website: winterkongress.ch. The videos are up at media.ccc.de – already one excellent recap, in the form of cartoons, is available:

Following this example, I will add my commentary here to a few photos and my slides.





In the Kitchen of ethical AI
My talk was a medley about 3 "cooks" who are helping us to upgrade from Open Data to Public AI, and was already submitted last year: on a private basis, not representing the opinion of an employer (this applies naturally to this whole blog). You can find the original description on the Winterkongress 2026 program with my slides and recording in German, with a translation that follows below.
First, I would like to express my heartfelt gratitude to Patrick "packi" Stählin, software engineer, long time contributor to open data, digital politics campaigner and City Councillor in Zürich. I couldn't ask for a better guide and moderator of my session at the Congress! Likewise my thanks go out to Danilo & team at the Coredump hackerspace in Rapperswil, whose open stack I used to prepare my presentation and interactive elements.
With apologies for my neglecting to inclusively gender the word cook (Köche) - I trust that everyone could see that I was referring to the metaphorical cook, and am very conscious of the fact that Köchinnen of all genders and orientations deserve our respect.
Video recording of the talk in German
In my brief introduction, I looked back at my career spanning the past decade as activist for freelancer, educator, maintainer and supporter of the open data movement. About ten years ago I helped to run an (un)conference in Lausanne, at which there was not a single mention of AI in the programme, though I'm quite sure it was mentioned at least in one keynote. We were already quite involved with data quality, the politics of knowledge, the philosophy of open access at the time.

Readers of this blog know that the Swiss {ai} Weeks in 2025 were the moment at which I found a way to connect my passion for open data and civic tech with the emerging field of (fully) open source AI. I shared a little bit of this background, which can be gleamed in my posts here. We have covered a lot since those events a half a year ago, but the fundamental questions remain.
Enough with the nostalgia, what are the issues on the table today?
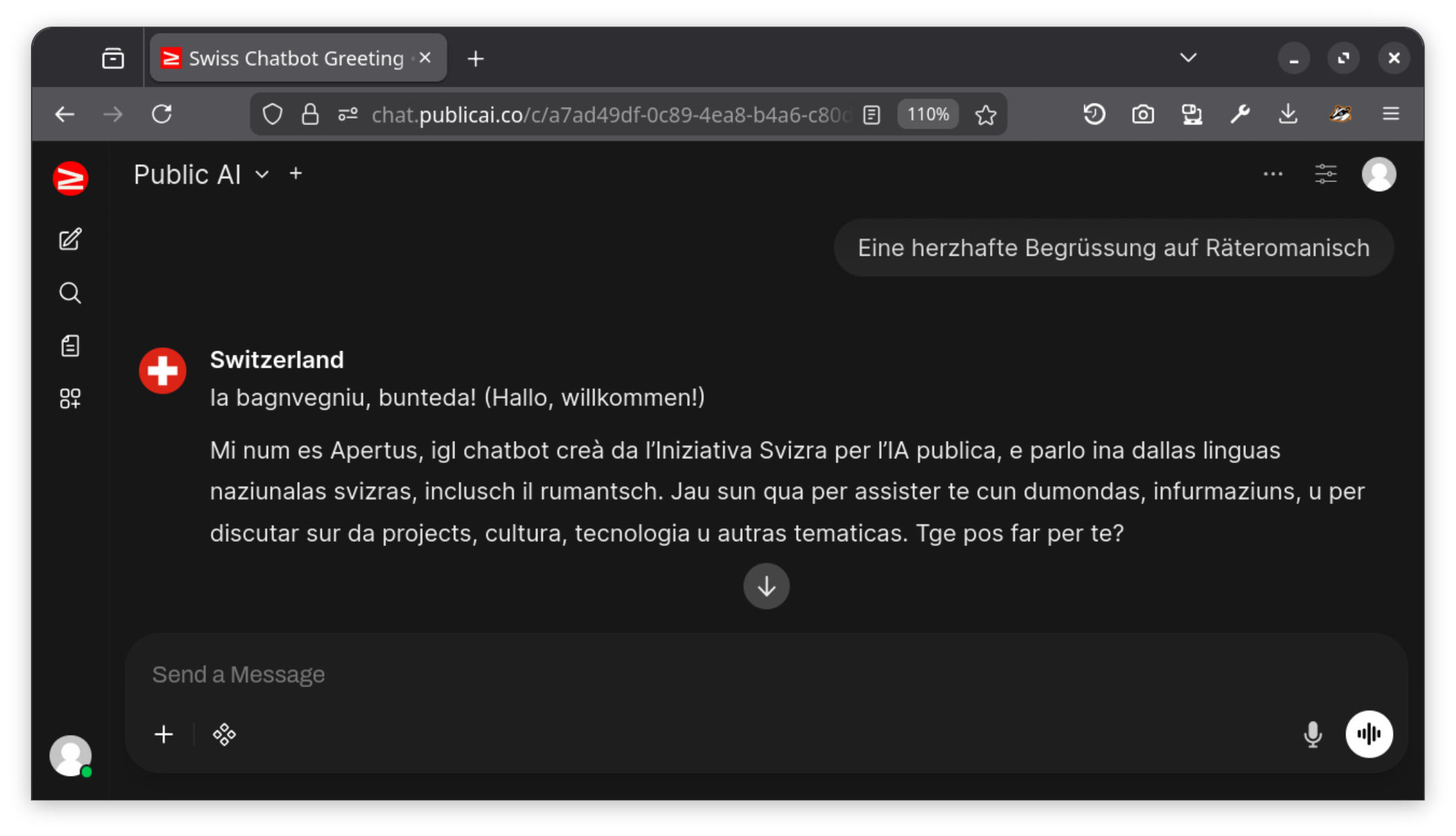
Ahead of the talk, I ran a set of openly shared prompts on Apertus 70B on the Public AI inference utility, and shared the full transcript with my audience. You can access them without logging in here:

The original context can be seen after logging in with a free Public AI account on chat.publicai.co

- The Model: an academic foundation
- Inference: the factory, public infrastructure
- Cooperative: people are engage in the formation of a civil society
These three "chefs" are covered individually in the following sections, along with a musical recommendation.
1 The Model
An academic foundation is the first step in our critical inquiry.
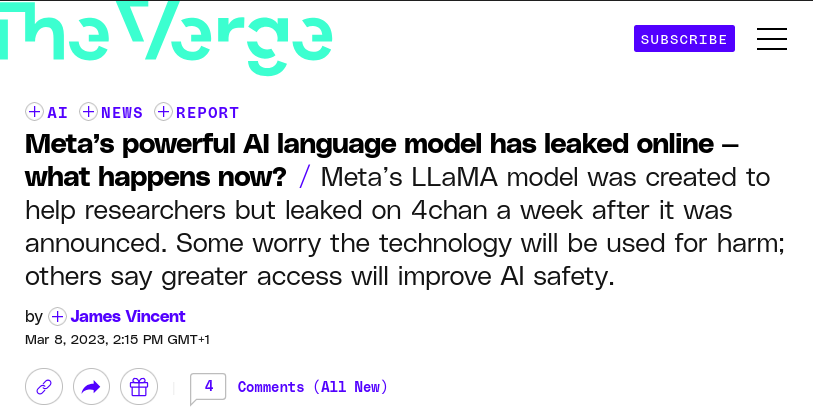
A look back at the now historic leak of the famous LLaMA open weight AI model. A number of risks are invoked that the technology could be used maliciously, with Meta defending its decision to open-source the model as necessary for advancing research, but the leak highlights the difficulty of balancing openness and responsible AI development.
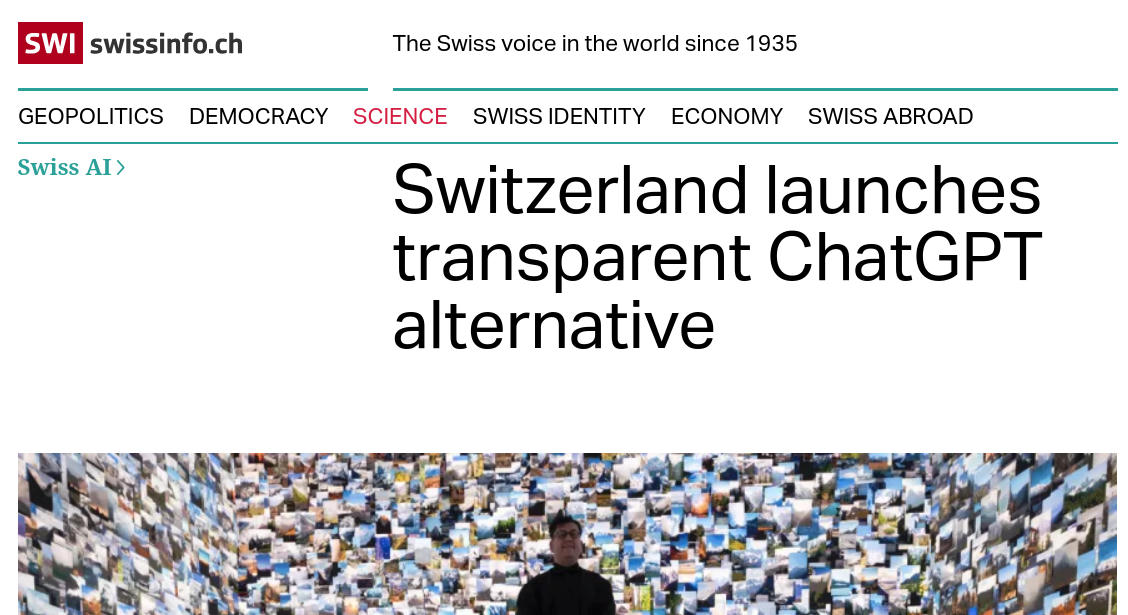
The media reception was quite far reaching, and somewhat misguided. It is symptomatic of a social sphere that is both fed up with AI news, as well as eagerly latching onto promising new developments. The majority of articles in swissinfo are critical of the model and its development.
#responsibleAI
Responsible Development
With Open Source AI, the protection of personal data and the focus on transparent data usage are emphasised. These solutions aim to actively address data protection concerns and make LLM training transparent to the public. The user community accordingly promotes transparent guardrails and ethical use with FOSS-based deployment.

Often missed on page 115 of the Tech Report, this rather short, dense and remarkable document is both a key element of the guardrails of the Apertus model, and a vision of how Swiss AI could serve to become a global foundation. The digital society should take note and contribute to these constitutional efforts, which parallel similar philosophic prompt-engineering efforts around the world.
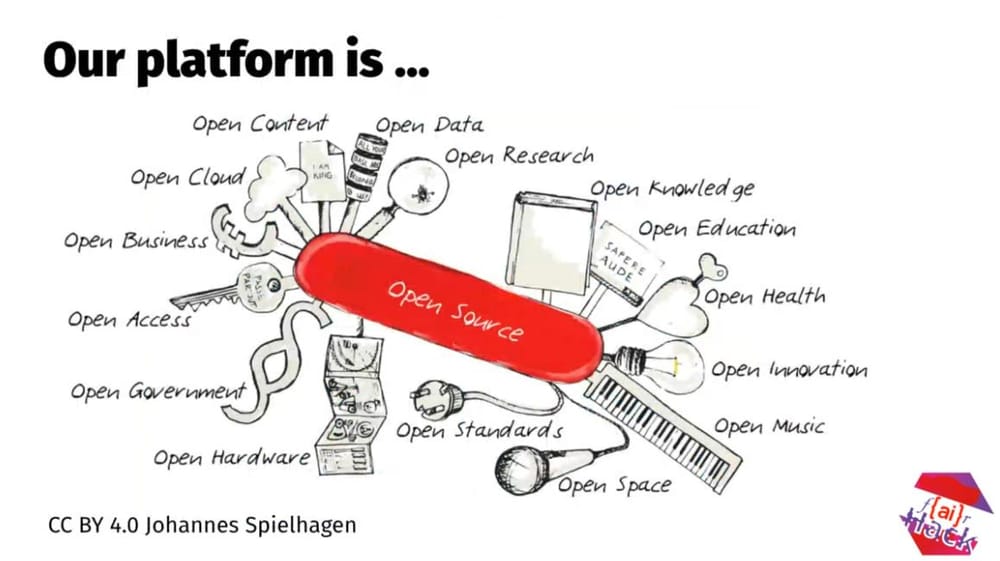
https://log.alets.ch/111/#platform
When we make a commitment to open source, we need to - like in this picture by Johannes Spielhagen - prepare to think about a wide range of factors in openness. How open can you go? With the "f{ai}R Hack" badge, I want to challenge participants of hackathons to push the envelope here. You can access all the source code of Apertus and Public AI on Hugging Face and GitHub.
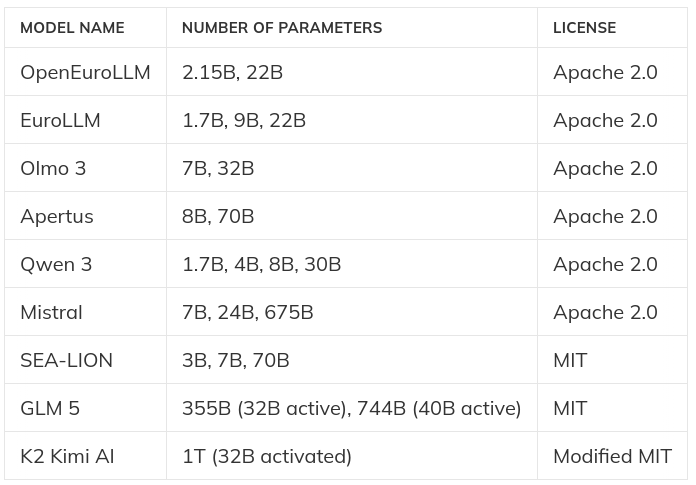
In this chart, from my previous blog post here, you can learn at a glance about the world of Open Source LLMs, the international efforts that fuel their development, and how Switzerland can play host and champion of this important community. Not all LLMs are made alike, and a plethora of technical and legal questions need to be explored in the exchanges.
#datacollectives
Data at the heart of AI
Data is the fuel of AI, but its use is often opaque. Platforms like Hugging Face place a strong emphasis on open and responsible data use, using legally compliant, open data sources and enabling all users to trace the use of data.
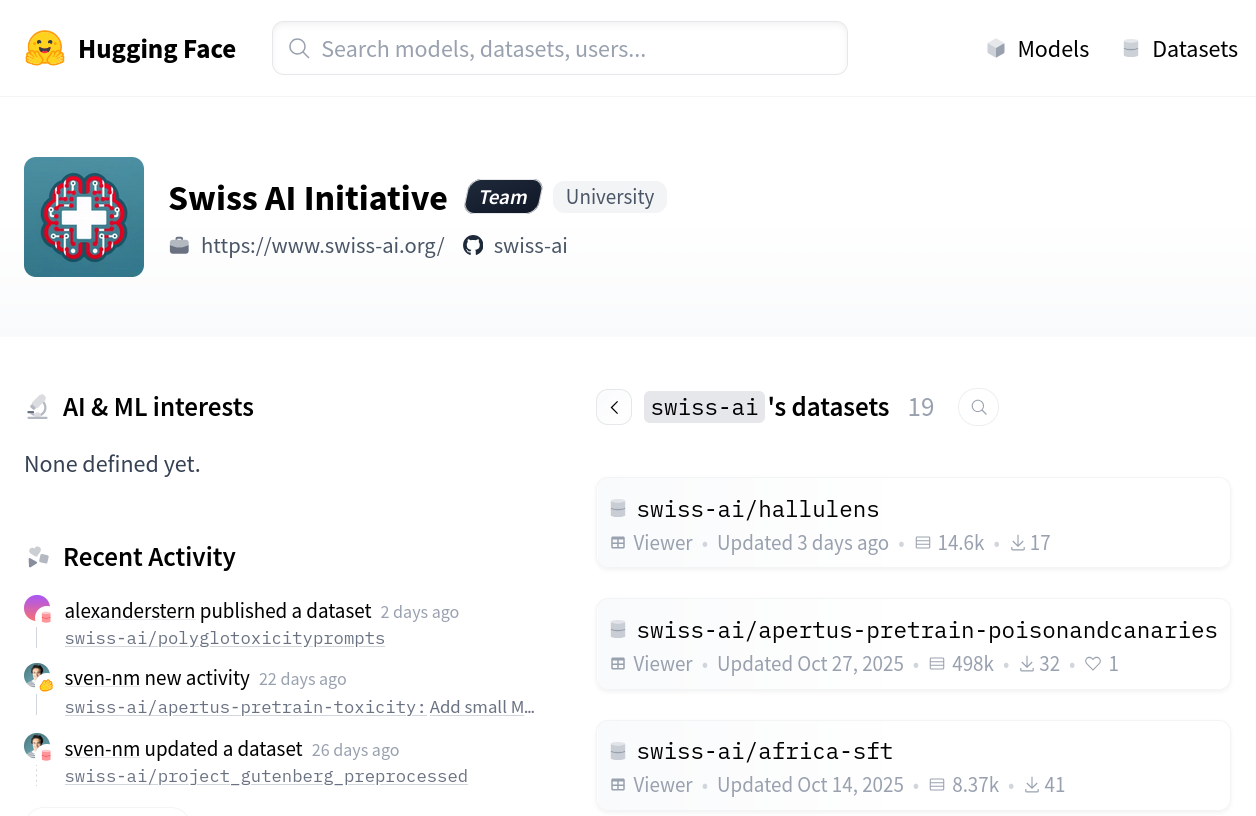
https://huggingface.co/swiss-ai/datasets
Here is where you can find and explore the key datasets that are being used to train the Apertus models. Running on Hugging Face, this is the front page of a powerful open data portal. In the next slides I dive into some of its functionality and show how it can be investigated further.
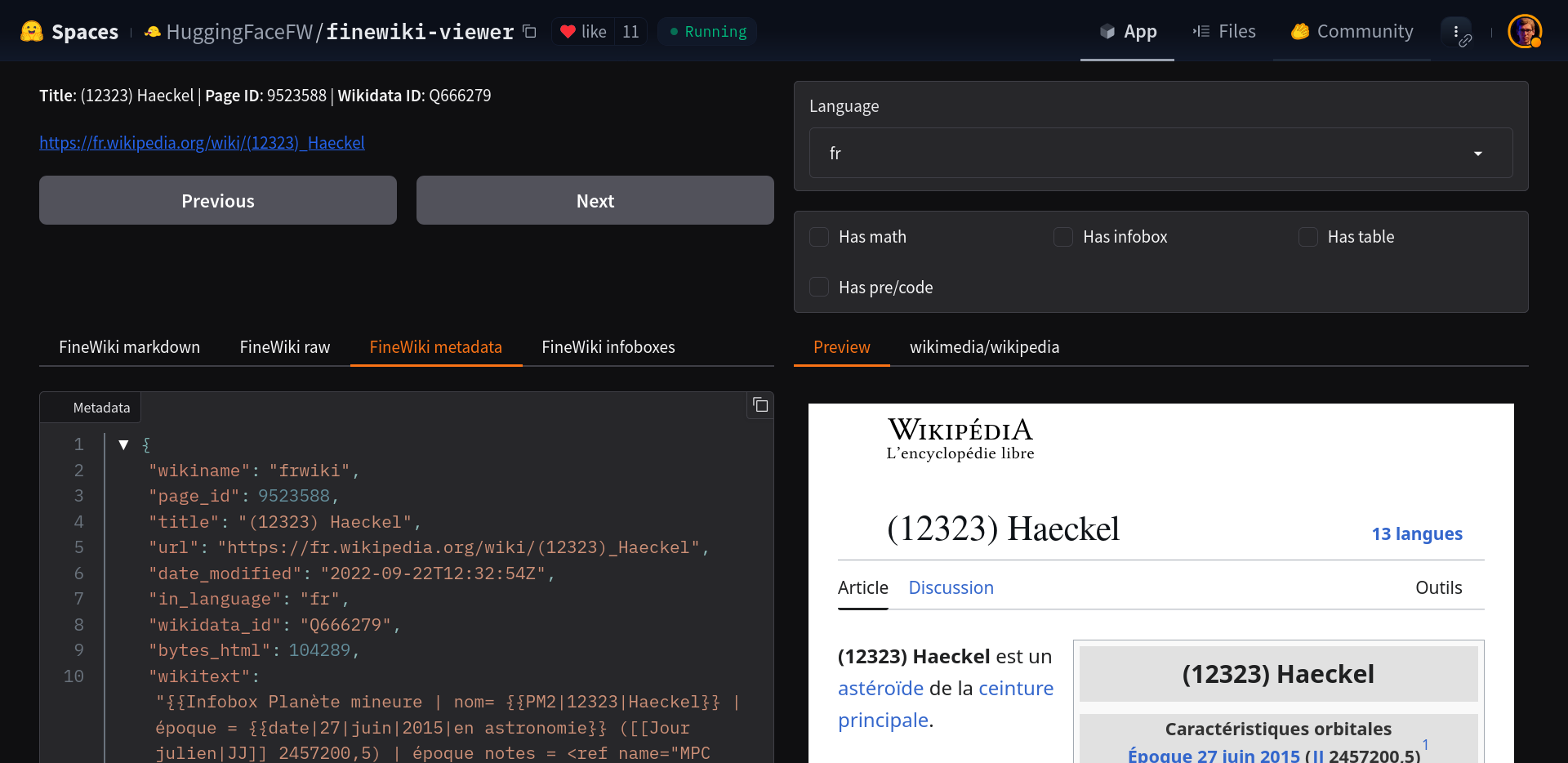
Here you can see how a Wikipedia article is represented in the FineWiki project. A number of such helpful tools exist in the form of Hugging Face Spaces. Some of them go more into the security or performance direction. I have one of my own for testing Apertus, and would be happy to see what you come up with.
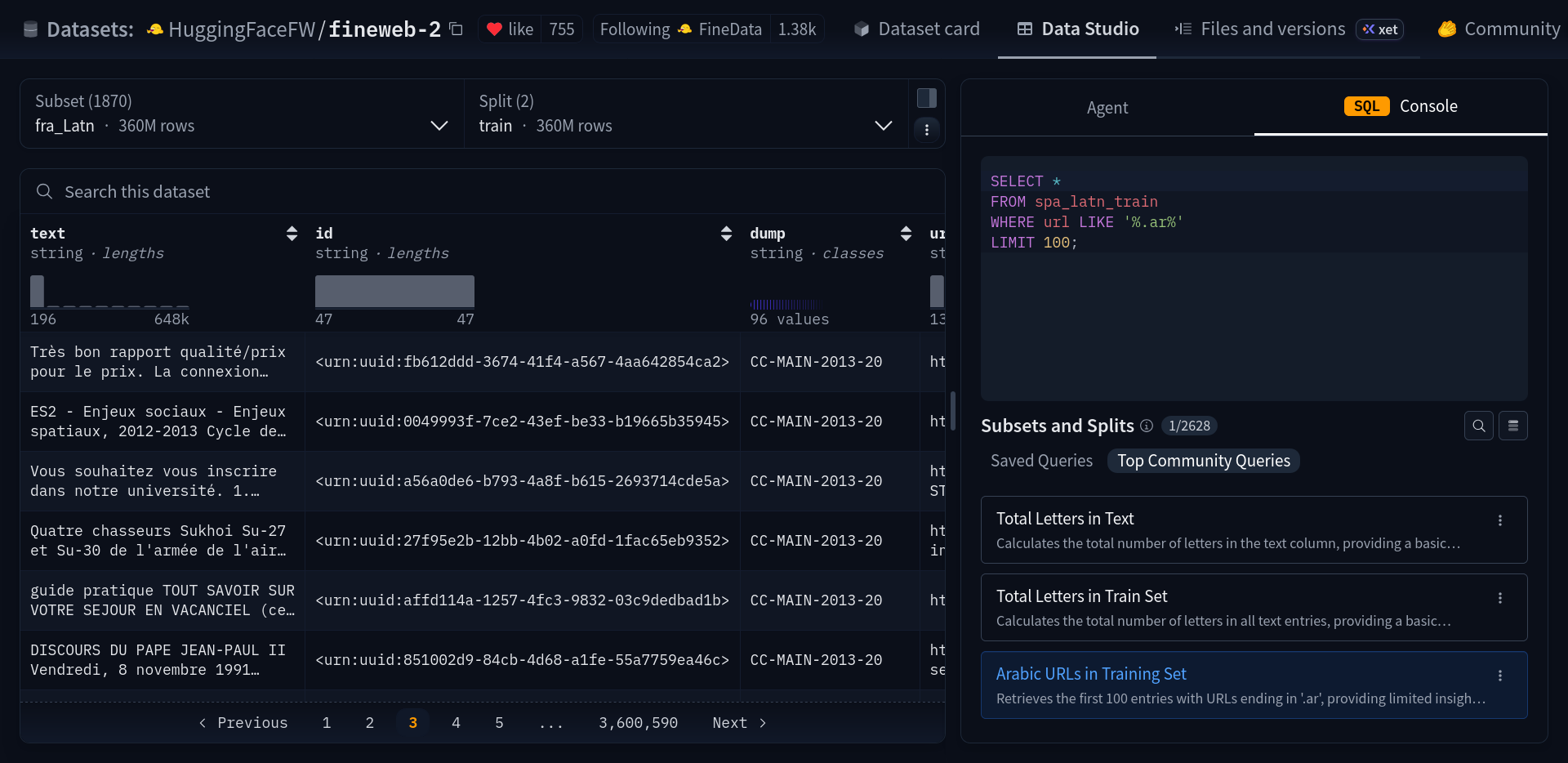
Here is the multi-billion-row dataset being explored directly in the web browser, even with the ability to run SQL to browse the data. This powerful capability can be used to hold AI developers accountable, discover security or bias problems, and contribute to the "data mix" of open models.
#limitstogrowth
Less is More
ETH research shows that less can be more – selected, open data sources often offer sufficient performance for general applications without compromising data protection more. The challenges of the Data Compliance Gap are addressed through focused data collection and transparent processes. Smaller models are also well-suited for targeted purposes.
https://log.alets.ch/110/ (LM Studio)
I've written a couple of blog posts on using Apertus on a local machine. The trouble is, not everyone can afford - or wants - a laptop with the capabilities of running such a model. Other people find the 8B version far too constrained to be of use. In fact this is a mostly overlooked strength of the initial release of the model, and has been put to good use in certain contexts, like research automation and edge computing.
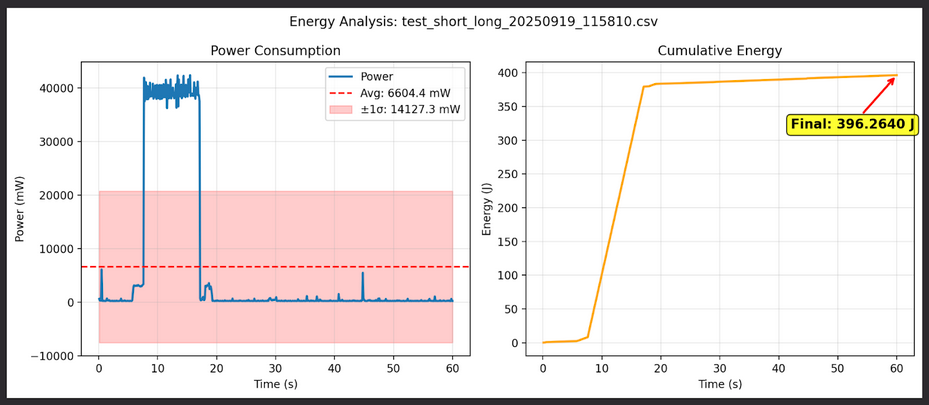
Running on a more powerful Mac Mini, this team in Bern tested the energy consumption of Apertus, comparing it to that of a current LLaMA model with similar specifications. This is the kind of due diligence that needs to be done to ensure the concept of Green IT delivers a tangible impact through more sustainable use of AI technologies. It's not easy to run these benchmarks, but we should try to do more as a community.
2 Inference
#ethicalalternative
Transparent Responsibility
A non-profit Inference Utility prioritises transparency and open source over the continuous accumulation of training data, or even pure performance offerings. Open models provide a trustworthy, understandable system for many. Users have control over data usage and model responses.
Using this flexible interface, a number of advanced parameters can be set to tweak the responses of LLM. This is not only the bread and butter of prompt engineering, it is the way forward for a more responsive and AI-literate user base. Not everyone needs to be a power user, but people should at least be aware of what kind of defaults they are being given. Support communities should spring around helping people to find a balance of temperature and context that meets their needs.

The Public AI network is a growing coalition working to bring about public AI internationally. As a supporter, I share their aim to ensure public capacity-building is part of the conversation about AI design, policy, and funding, help coordinate formal research and citizen science efforts in the ML community, support policymakers and technical teams, and help to organize the the broader movement for public AI. Is this just Open AI done right?
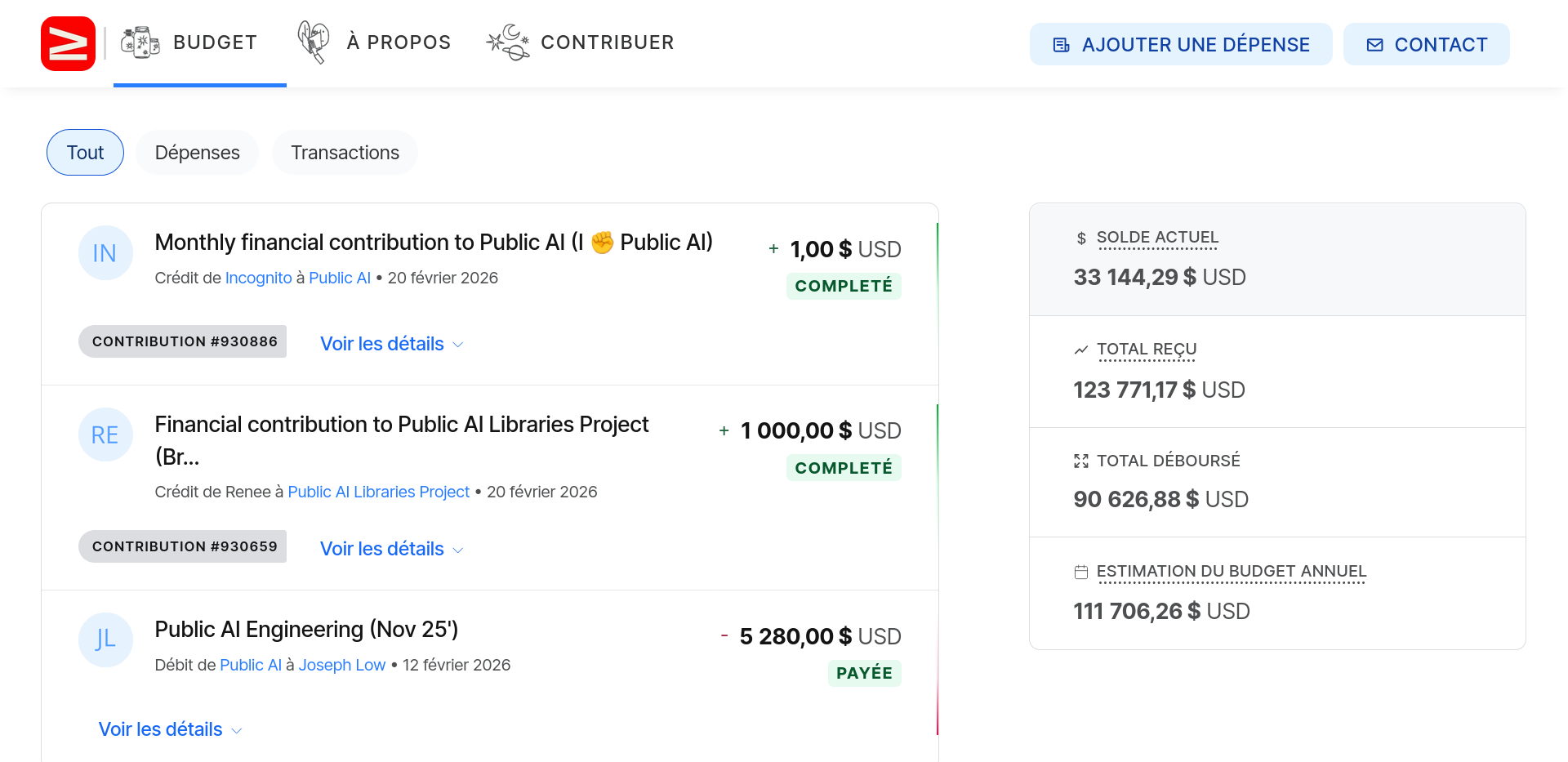
I briefly showed the transparency commitment of the project made evident through the open accounting on their crowdfunding platform. In the next section, I will tell you more about Public AI's plans to incorporate a Swiss chapter.
3 Cooperative
#hackintegration
Trustable Integration
With Apertus, Switzerland has once again proven itself to be a small country that can achieve great things, but it needs much more public support to operate LLM integration in an open data space. Through collaboration with research, administration and civil society, trustworthiness and performance are set to continue to increase hand in hand.
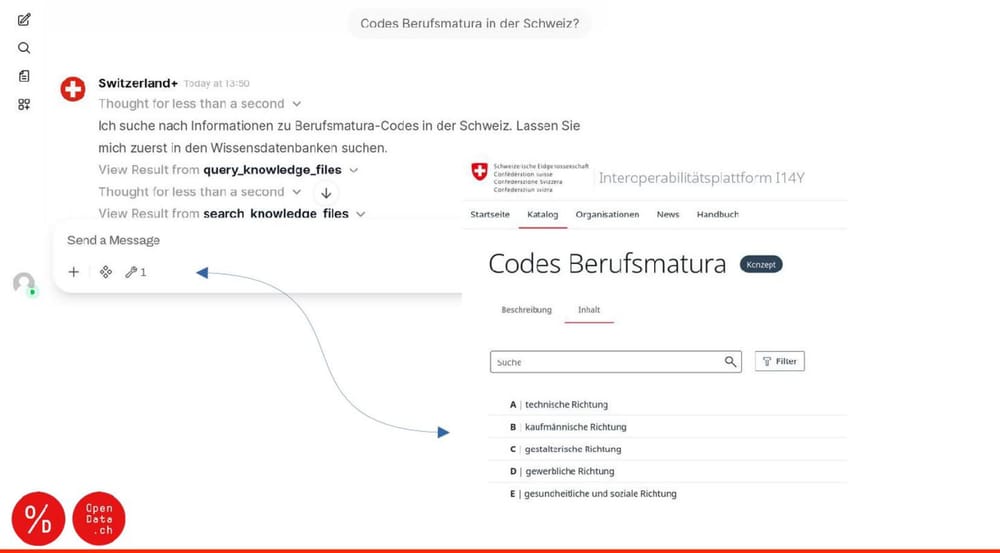
In this example, I show the missing link between advanced agentic (MCP server) capabilities of Public AI infrastructure, and a mandate the Swiss government to create interoperable services. In a nutshell, this is an opportunity for both tech companies and the civic tech sector to, not just add more duct tape, but to potentially do it better and faster than in previous waves of public sector digitization.
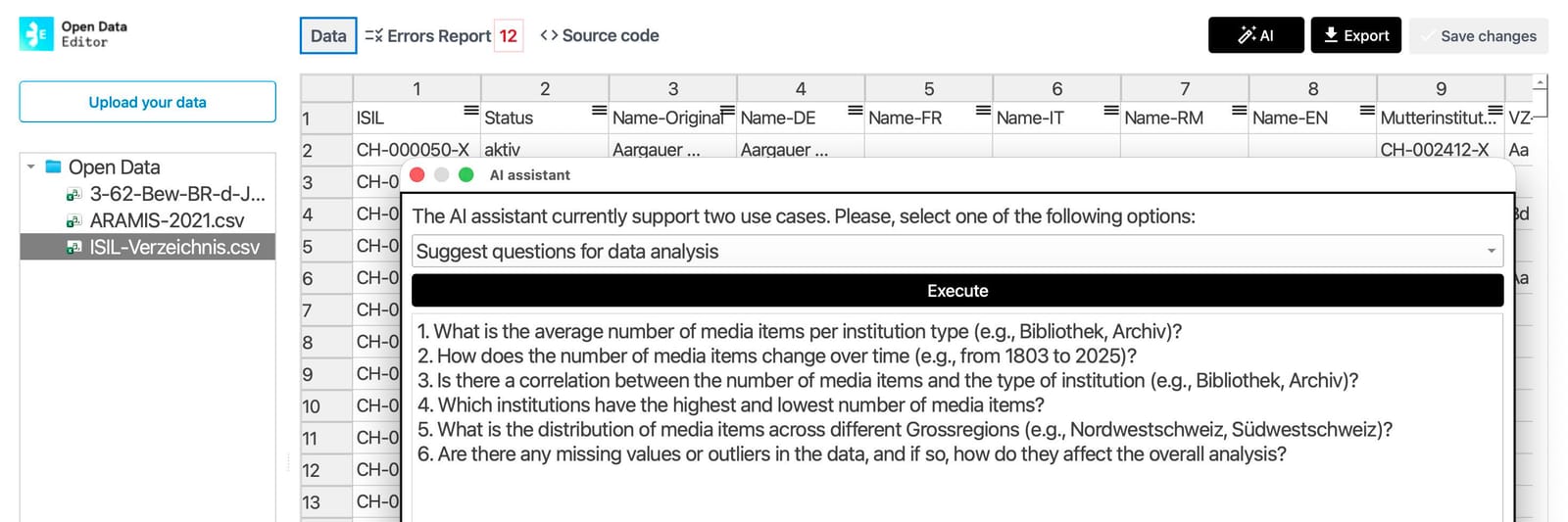
With this screenshot of the Apertus model helping to improve the quality of an Open Government Dataset with the local AI assistant of OKFN's Open Data Editor, I am showing that a big part of this is already available, without fancy proprietary standards, and accessible to a non-technical audience.

This is a glimpse of a survey by Anna Sotnikova (EPFL NLP lab) that was embedded in the Public AI service, and to which around 70 users have responded. It is a glimpse of the kind of insights we should expect from research collaborations. And one of the easiest ways that we as users can contribute to the science and practice of LLMs.
#AIcooperative
Participative Aspects
Everyone should contribute to ensuring that AI in our country reflects values such as openness, transparency and equality. Through open participation, transparent practices and community-oriented research, we are jointly shaping a future in which AI benefits everyone AND belongs to many. Join us! We invite everyone to become part of the Public AI Switzerland cooperative – a collaborative initiative that promotes ethical AI development.
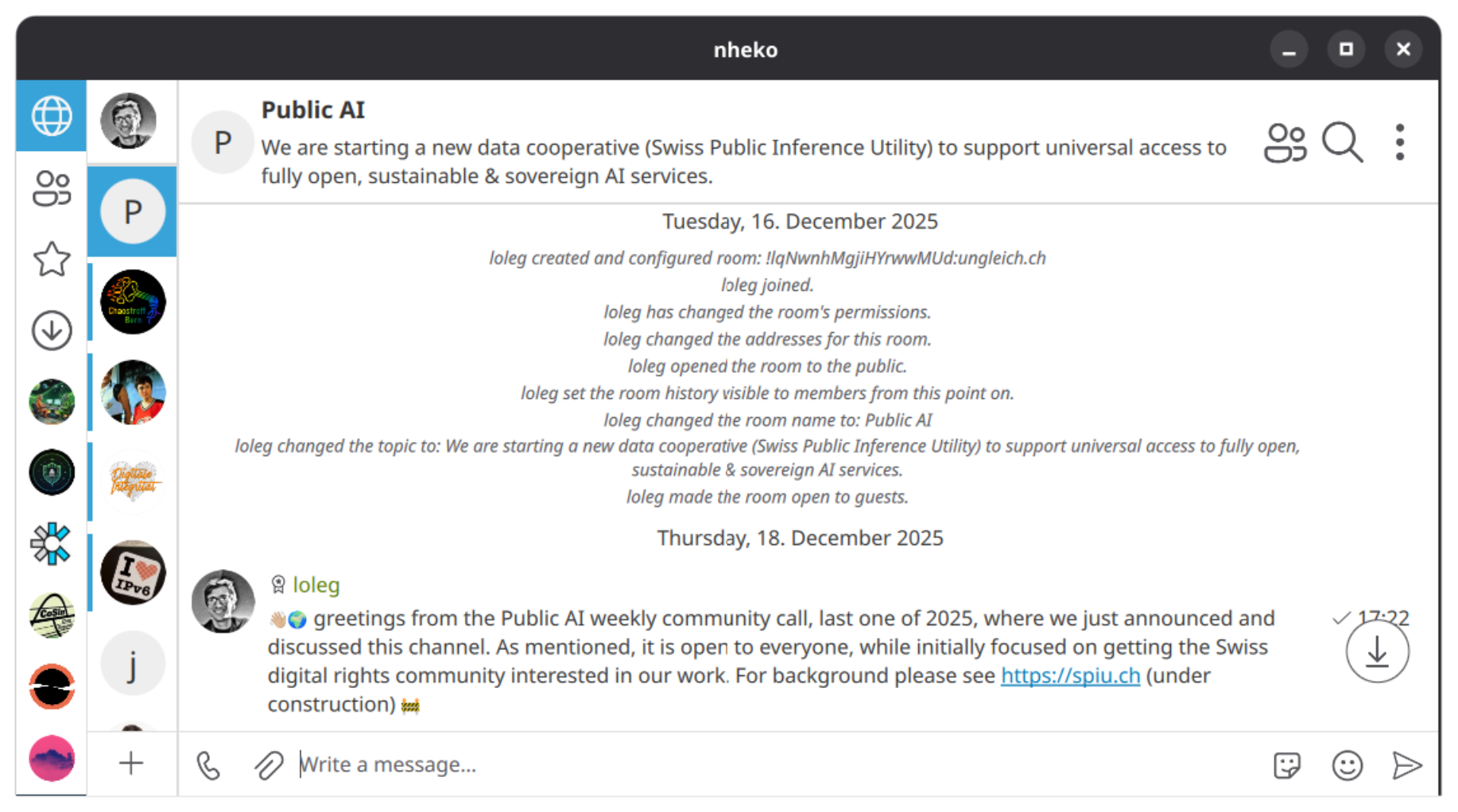
Matrix: #spiu@ungleich.ch
We have a channel, currently rather quiet, but I encourage folks in the Digital Society community (especially those who are understandably allergic to proprietary clouds and chat-clients) to join us here. I also invited the people gathered in front of me to come back in a week for a launch event in Zürich.
Further reading
- 🌐 publicai.ch - Public AI Switzerland
- 📕 publicai.network - Public AI Network
- 📗 arXiv:2410.17481v1 - Srivastava et al
- 📙 KI als öffentliches Gut - SRF 26.1.2026
- 📘 Abundance vs. Scarcity - Paul Keller 2026
My slides were created with the help of Apertus 1.0 70B on Public AI.
Don't disdain - disclaim!




 The works on this blog are licensed under a Creative Commons Attribution 4.0 International License
The works on this blog are licensed under a Creative Commons Attribution 4.0 International License